SIMD 演算用のインテル® C++ クラス・ライブラリーは、「ハードウェアとソフトウェアの要件」に示した各種プロセッサー用の基本命令を利用するための便利なインターフェイスとなります。 プロセッサー命令のこのような拡張機能によって、SIMD (single instruction-multiple data) 手法を用いた並列処理が可能になります。次の図は、SIMD のデータフローを示しています。
SIMD のデータフロー
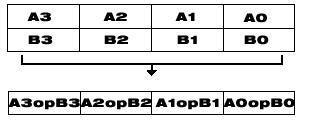
特にこの命令では、命令 1 つで演算が 4 回実行できるため、効率が 4 倍改善されます。
このような新しいプロセッサー命令は、インライン・アセンブリー、組込み関数、または C++ SIMD クラスのいずれを使用しても実装できます。 その 3 種類のインターフェイスについて、32 ビット浮動小数点値を 4 つ加算するのに必要なコーディングを比較してみてください。
インライン・アセンブリー、組込み関数、クラス・ライブラリーの比較
インライン・アセンブリー |
組込み関数 |
SIMD クラス・ライブラリー |
|---|---|---|
... __m128 a,b,c; __asm{ movaps xmm0,b movaps xmm1,c addps xmm0,xmm1 movaps a, xmm0 } ... |
#include <xmmintrin.h> ... __m128 a,b,c; a = _mm_add_ps(b,c); ... |
#include <fvec.h> ... F32vec4 a,b,c; a = b +c; ... |
この表は、単精度浮動小数点値を 4 つ加算するコードについて、インライン・アセンブリー、組込み関数、および SIMD クラス・ライブラリーを用いた場合をそれぞれ示したものです。 インテル® C++ SIMD クラス・ライブラリーでコーディングをするのがいかに簡単かが分かります。 キー入力の数が減り、コードの行数が減るだけでなく、表記についても C++ の標準表記と似ているため、他の手法よりも簡単に実装できます。