balanced アフィニティー型は、インテル® MIC アーキテクチャーで特に役立ちます。 シングルソケットのシステムの場合のみ CPU 上でサポートされます。
注
OpenMP* 環境変数 OMP_PROC_BIND=spread は、KMP_AFFINITY=balanced と似ており、マルチソケット CPU システムを含むすべてのプラットフォームで利用できます。
この設定では、scatter 型と同様に、OpenMP* ランタイムは、すべてのコアに少なくとも 1 つのスレッドが配置されるまで、別のコアにスレッドを配置します。 ただし、ランタイムが同じコアで複数のハードウェア・スレッド・コンテキストを使用する際、balanced 型では OpenMP* スレッドの番号が互いに隣接していることが保証されるのに対して、scatter 型では保証されません。
次の図は、3 コアのシステムで 6 つの OpenMP* スレッドを compact、scatter、balanced アフィニティー型で割り当てた場合を示しています。
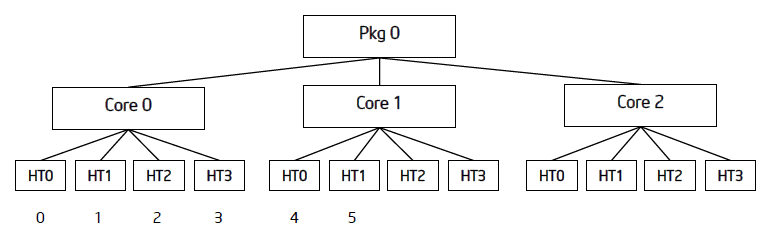
インテル® MIC アーキテクチャーでは、通常はスレッドの前にコアを使用して割り当てを行うと効果があります。compact 型では未使用のコアが残るため、最適な結果は得られません。
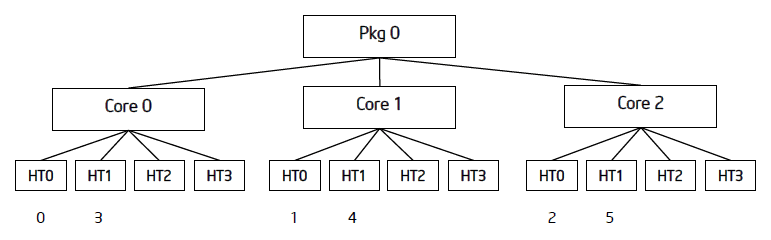
scatter 型はスレッドの前にコアを使用して割り当てを行うため、compact 型よりも優れています。 ただし、scatter 型では異なるコアの (つまり、キャッシュを共有しない) スレッドに ID が隣接するスレッドが割り当られます。 ID が隣接するスレッドは密接に関連するデータを処理することが多いため、これらのスレッドを異なるコアに配置するのは最良の方法ではありません。
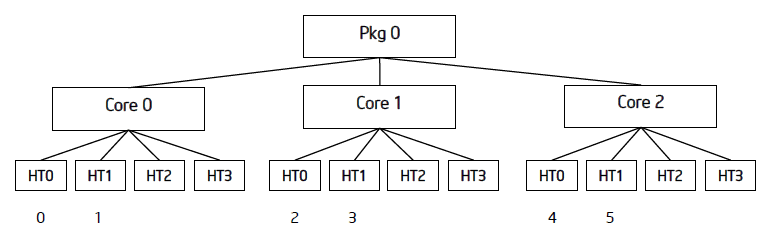
balanced 型では、コア間でバランスの取れたスレッド割り当てが行われ、コアに割り当てられるスレッドが互いに隣接しています。 このため、スレッドが近くに格納されているデータにアクセスする場合のキャッシュ効率が高くなります。
アフィニティーのチューニングは、複雑なマシン固有のプロセスです。インテル® MIC アーキテクチャーでは、balanced アフィニティー型を使用するのが合理的です。
balanced アフィニティー型は、シングルソケットのシステムの場合のみ CPU 上の OpenMP* ランタイムでも認識されサポートされます。
MIC_ENV_PREFIX が設定されていない場合、環境変数 KMP_AFFINITY で balanced アフィニティー型を使用すると、コプロセッサーにも同じ型が使用されます。 ただし、マルチソケット CPU では次のランタイム警告が出力されることがあります。
OMP: 警告 #230: KMP_AFFINITY: 安定したアフィニティーが利用できません。
インテル® MIC アーキテクチャー環境でのみ balanced アフィニティー型を設定するには、MIC_ENV_PREFIX=prefix を使用して特定のプリフィクスを割り当ててから、prefix_KMP_AFFINITY を balanced に設定します。