インテル® Cilk™ Plus は古い機能 (非推奨) です。代わりに、OpenMP* またはインテル® TBB を使用してください。詳細は、「インテル® Cilk™ Plus の代わりに OpenMP* またはインテル® TBB を使用するためのアプリケーションの移行」を参照してください。
インテル® Cilk™ Plus プログラムのシリアル/並列構造を DAG などで表すことができたら、プログラムのパフォーマンスとスケーラビリティーの解析を開始します。
次の図のような複雑なプログラムについて考えてみます。
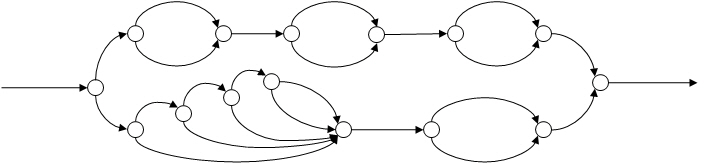
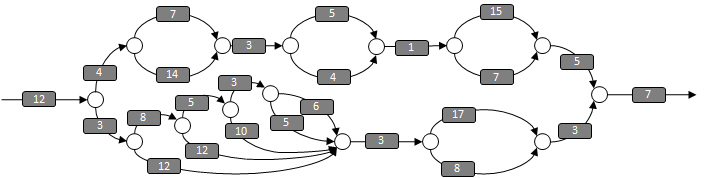
この DAG は、あるインテル® Cilk™ Plus プログラムの並列構造を表したものです。この DAG に対応するプログラムを作成する上で、各ストランドのラベルとして、それぞれの実行にかかる時間 (ミリ秒) を追加しておくと便利です。
ワーク
プログラムを完了するのに必要なプロセッサー時間の合計は、各ストランドの実行時間の合計になります。この値はワークとして定義されます。
この DAG において、25 個のストランドの作業は 181 ミリ秒です。このプログラムをシングルコア (プロセッサー) で実行すると 181 ミリ秒かかります。
スパン
スパンはクリティカル・パスの長さとも呼ばれ、プログラムの開始から終了までに最も時間がかかるパスのことです。次に示すように、この DAG のスパンは 68 ミリ秒です。
理想的な状態 (スケジュール・オーバーヘッドがないなど) で、利用可能なプロセッサー・コア数が無制限の場合、このプログラムは 68 ミリ秒で実行できます。
ワークとスパンを使用して、マルチコア・プロセッサーでのインテル® Cilk™ Plus プログラムのスピードアップとスケーラビリティーを予測することができます。
インテル® Cilk™ Plus プログラムを解析する場合は、さまざまなプロセッサー・コア数でのプログラムの実行時間を考慮する必要があります。次の情報が役に立ちます。
T(P): P 個のプロセッサー・コアでのプログラムの実行時間
T(1): ワーク
T(∞): スパン
デュアルコア・プロセッサーでの実行時間は、常に T(1)/ 2 よりも小さくなることはありません。一般的に、ワークには次の法則が当てはまります。
T(P) >= T(1)/P
同様に、P 個のプロセッサー・コアでの実行時間は、常にプロセッサー・コア数が無制限の場合の実行時間よりも小さくなることはありません。そのため、スパンには次の法則が当てはまります。
T(P) >= T(∞)
スピードアップと並列性
デュアルコア・プロセッサーでプログラムの実行速度が 2 倍になった場合は、スピードアップは 2 となります。つまり、P 個のプロセッサー・コアでのスピードアップは次のようになります。
T(1)/T(P)
この式では、T(P) と比べて T(1) のほうがより速く増加すると、ワークの増加に伴い実行速度がより速くなります。アルゴリズムによっては、追加のプロセッサー・コアを活用するために追加の処理が発生します。通常、そのようなアルゴリズムは、シングルコアまたはデュアルコア・プロセッサーでは対応するシリアル・アルゴリズムよりも遅く、3 つ以上のプロセッサー・コアでスピードアップが見られます。これは一般的なケースではありませんが、知っておくとよいでしょう。
スピードアップは、プロセッサー・コア数が無制限の場合に最大になります。並列性は、プロセッサー・コア数が無制限である場合を想定して、スピードアップを仮定することであると定義できます。そのため、並列性は次のように定義できます。
T(1)/T(∞)
並列性には期待できるスピードアップに上限があります。例えば、並列コードの並列性が 2.7 の場合、2 つまたは 3 つのプロセッサー・コアではスピードアップが見込まれますが、4 つ以上のプロセッサー・コアではそれ以上のスピードアップを見込むことはできません。このため、少数のコア向けにチューニングされたアルゴリズムは、多数のコアでスケーリングしません。一般的に、並列性が利用可能なプロセッサー・コア数の 5 ~10 倍よりも小さい場合、スケジューラーはすべてのプロセッサー・コアをビジーに保つことはできないため、直線的なスピードアップは期待できません。