インテルのランタイム・ライブラリーには、OpenMP* スレッドを物理処理ユニットにバインドする機能があります。このインターフェイスは、KMP_AFFINITY 環境変数により制御されます。システム (マシン) のトポロジー、アプリケーション、オペレーティング・システムによってスレッド・アフィニティーはアプリケーションの速度に大きく影響します。
スレッド・アフィニティーは、特定のスレッド (仮想実行ユニット) をマルチプロセッサー・コンピューターの物理処理ユニットのサブセットに限定します。マシンのトポロジーにより、スレッド・アフィニティーはプログラムの実行速度に大きな影響を与えます。
スレッド・アフィニティーは、Windows* システムとスレッド・アフィニティー対応カーネルを持つ Linux* システムのバージョンでサポートされていますが、macOS* ではサポートされていません。
インテルの OpenMP* ランタイム・ライブラリーには、OpenMP* スレッドを物理処理ユニットにバインドする機能があります。このバインド機能は、3 種類のインターフェイスで使用できます。これらのインターフェイスは総称して、インテルの OpenMP* スレッド・アフィニティー・インターフェイスと呼ばれます。
高レベルのアフィニティー・インターフェイスでは、環境変数を使用してマシントポロジーを特定し、マシンの物理的位置に基づいて OpenMP* スレッドをプロセッサーに割り当てます。このインターフェイスは、KMP_AFFINITY 環境変数により全体が制御されます。
中レベルのアフィニティー・インターフェイスでは、環境変数を使用してどのプロセッサー(整数 ID) が OpenMP* スレッドにバインドされるかを明示的に指定します。このインターフェイスは、gcc* の GOMP_AFFINITY 環境変数と互換性があり、KMP_AFFINITY 環境変数を使用して起動することもできます。GOMP_AFFINITY 環境変数は、Linux* システムでのみサポートされています。ただし、Windows* または Linux* のユーザーにも KMP_AFFINITY 環境変数によって同様の機能が提供されます。
低レベルのアフィニティー・インターフェイスでは、API を使用して OpenMP* スレッドに OpenMP* ランタイム・ライブラリーを呼び出しさせ、実行するプロセッサー・セットを明示的に指定することができます。このインターフェイスは、Linux* システムの sched_setaffinity および関連関数や Windows* システムの SetThreadAffinityMask および関連関数と本質的に似ています。また、KMP_AFFINITY 環境変数の特定のオプションを指定して、低レベル API インターフェイスの動作を指定できます。例えば、KMP_AFFINITY アフィニティー・タイプを無効にすると、低レベルのアフィニティー・インターフェイスが無効になります。また、KMP_AFFINITY や GOMP_AFFINITY 環境変数を使用して、初期アフィニティー・マスクを設定してから、低レベル API インターフェイスでマスクを取得することができます。
次の用語がこのセクションで使用されています。
マシン上のプロセシング要素の合計数は、OS スレッド・コンテキストの数と呼ばれます。
各プロセシング要素は、オペレーティング・システム・プロセッサーまたは OS proc と呼ばれます。
各 OS プロセッサーには、OS proc ID と呼ばれる一意の整数の識別子が関連付けられます。
パッケージとは、シングルまたはマルチコアのプロセッサー・チップを指します。
OpenMP* グローバルスレッド ID (GTID) は、インテルの OpenMP* ランタイム・ライブラリーにより認識されるすべてのスレッドを一意に特定する整数です。ライブラリーを最初に初期化するスレッドは、GTID 0 です。その他すべてのスレッドがライブラリーによって作成される通常の場合で、入れ子構造の並列性がないときは、n-threads-var - 1 (範囲は 1 から ntheads-var - 1 まで) の新しいスレッドが GTID により作成されます。各スレッドの GTID は omp_get_thread_num() 関数によって返される OpenMP* スレッド番号と同じです。高レベルおよび中レベルのインターフェイスは、この概念に大きく基づいています。したがって、有用性は入れ子構造の並列性を含むプログラムに限定されます。低レベルのインターフェイスでは、GTID の概念を利用していないため、任意の並列化レベルを含むプログラムで使用できます。
一部の環境変数はインテル製マイクロプロセッサーおよび互換マイクロプロセッサーで利用可能ですが、インテル製マイクロプロセッサーにおいてより多くの最適化が行われる場合があります。
KMP_AFFINITY 環境変数
注
KMP_AFFINITY 環境変数は、後述の「低レベルのアフィニティー API」で説明されているように、最初の並列領域の前、または omp_get_max_threads()、omp_get_num_procs()、アフィニティー API 呼び出しを含む特定の API 呼び出しの前に設定する必要があります。
KMP_AFFINITY 環境変数には、次の一般的な構文が使用されます。
構文 |
|---|
KMP_AFFINITY=[<modifier>,...]<type>[,<permute>][,<offset>] |
例えば、マシン・トポロジー・マップをリストするには、KMP_AFFINITY=verbose,none を指定し、modifier に verbose、type に none を使用します。
次の表は、サポートされる引数のリストです。
引数 |
デフォルト |
説明 |
|---|---|---|
noverbose respect granularity=core |
オプション。キーワードと指定子から構成されます。
<proc-list> の構文は、中レベルのアフィニティー・インターフェイスで説明されています。 |
|
none |
必須です。使用するスレッド・アフィニティーを示します。
logical と physical は推奨されていないタイプですが、下位互換性のためにサポートされています。 |
|
0 |
オプション。正の整数値です。type 値の explicit、none、disabled との使用は無効です。 |
|
0 |
オプション。正の整数値です。type 値の explicit、none、disabled との使用は無効です。 |
アフィニティー・タイプ
"type" は、唯一必須の引数です。
type = none (デフォルト)
OpenMP* スレッドは特定のスレッド・コンテキストにバインドされません。ただし、オペレーティング・システムでアフィニティーがサポートされる場合は、コンパイラーは OpenMP* スレッド・アフィニティー・インターフェイスを使用してマシンのトポロジーを特定します。KMP_AFFINITY=verbose,none を指定して、マシンのトポロジーマップをリストします。
type = balanced
scatter と同様に、すべてのコアに少なくとも 1 つのスレッドが配置されるまで、別のコアにスレッドを配置します。ただし、ランタイムが同じコアで複数のハードウェア・スレッド・コンテキストを使用する際、balanced では OpenMP* スレッドの番号が互いに隣接していることが保証されるのに対して、scatter では保証されません。このアフィニティー・タイプは、インテル® MIC アーキテクチャーで特に役立ちます。シングルソケットのシステムの場合のみ CPU 上でサポートされます。
注
OpenMP* 環境変数 OMP_PROC_BIND=spread は、KMP_AFFINITY=balanced と似ており、マルチソケット CPU システムを含むすべてのプラットフォームで利用できます。
type = compact
compact を指定すると、フリー・スレッド・コンテキストの OpenMP* スレッド <n>+1 は、OpenMP* スレッド <n> が割り当てられたスレッド・コンテキストにできる限り近いスレッド・コンテキストに割り当てられます。例えば、トポロジーマップで、ルートにより近いノードほど、スレッドをソートしたときに上位になります。
type = disabled
disabled を指定すると、スレッド・アフィニティー・インターフェイスを完全に無効にします。これにより、OpenMP* ランタイム・ライブラリーはアフィニティー・インターフェイスがオペレーティング・システムでサポートされていないかのように動作します。これには、kmp_set_affinity や kmp_get_affinity などのような、効果がなく、非ゼロのエラーコードが返される低レベル API インターフェイスが含まれます。
type = explicit
explicit を指定すると、proclist= modifier (このアフィニティー・タイプには必須) を使用して明示的に指定された OS proc ID のリストに OpenMP* スレッドが割り当てられます。「OS プロセッサー ID (GOMP_CPU_AFFINITY) を明示的に指定する」を参照してください。
type = scatter
scatter を指定すると、システム全体にわたってスレッドが均等に分配されます。scatter は、compact の逆です。そのため、マシンのトポロジーマップをソートするとノードリーフは最上位になります。
推奨されていないタイプ: logical と physical
logical と physical は廃止予定で、将来のリリースではサポートされなくなります。両方とも、下位互換性のためにサポートされています。
logical および physical では、整数値が 1 つしかない場合は、permute 指定子ではなく、offset 指定子と解釈されます。これに対し、compact と scatter では、整数値が 1 つのみの場合は permute 指定子と解釈されます。
logical を指定すると、OpenMP* スレッドを連続した論理プロセッサー (ハードウェア・スレッド・コンテキストとも呼ぶ) に割り当てます。このタイプは、permute 指定子が使えないことを除いては、compact と同等です。そのため、KMP_AFFINITY=logical,n は KMP_AFFINITY=compact,0,n と (granularity=fine 修飾子の有無にかかわらず) 同等です。
physical を指定すると、OpenMP* スレッドを連続した物理プロセッサー (コア) に割り当てます。コアごとに 1 つのスレッド・コンテキストしかないシステムの場合、logical と同じです。コアごとに複数のスレッド・コンテキストがあるシステムの場合、physical は permute 指定子が 1 に指定された compact と同じです。つまり、KMP_AFFINITY=physical,n は、KMP_AFFINITY=compact,1,n と (granularity=fine 修飾子の有無にかかわらず) 同等です。これは、コンパイラーがマップをソートしたときにマシンのトポロジーマップの最も内側のレベルを最も外側 (おそらくスレッド・コンテキスト・レベル) に入れ替えることを意味します。このタイプでは permute 指定子はサポートされません。
compact と scatter の例
次の図は、2 つのプロセッサーを搭載しているマシンを示しています。それぞれのプロセッサーには 2 つのコアがあります。各コアはインテル® ハイパースレッディング・テクノロジー (インテル® HT テクノロジー) 対応です。
また、次の図は、KMP_AFFINITY=granularity=fine,compact を指定したときに、OpenMP* スレッドがハードウェア・スレッド・コンテキストにバインドされる様子も示しています。
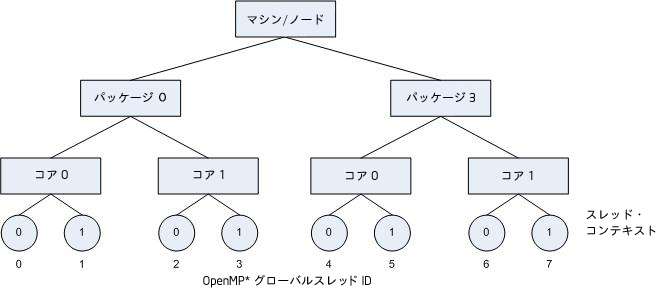
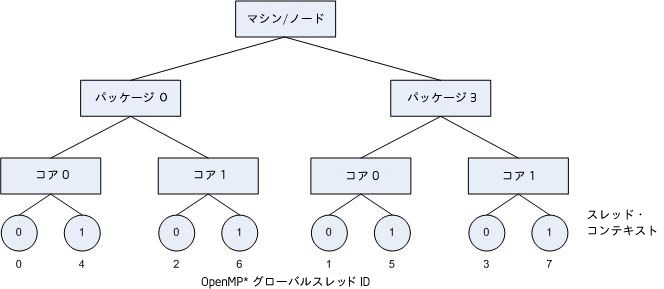
上図のシステムで scatter を指定すると、次の図のように、OpenMP* スレッドがスレッド・コンテキストに割り当てられます。これは、KMP_AFFINITY=granularity=fine,scatter を指定した結果です。
permute と offset の組み合わせ
compact と scatter の両方とも permute と offset が指定できます。ただし、1 つの整数だけを指定した場合は、コンパイラーは値を permute 指定子として解釈します。permute と offset の両方ともデフォルトは 0 です。
permute 指定子はマシンのトポロジーマップをソートしたときに最上位にするレベルを制御します。permute の値により、指定された番号の最上位レベルは最下位にマッピングされ、順位が入れ替わります。ツリーのルートノードは、ソート操作では個別のレベルとは見なされません。
offset 指定子は、スレッド割り当ての開始地点を示します。
次の図は、KMP_AFFINITY=granularity=fine,compact,0,3 を指定した結果を示しています。
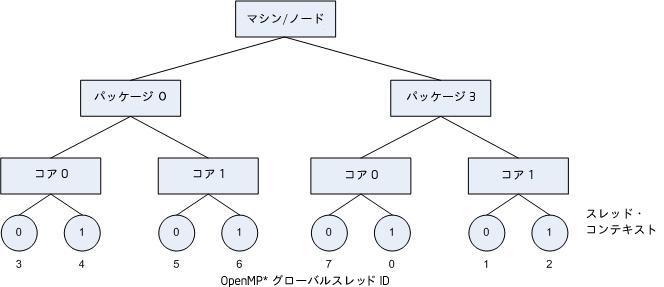
前述の例、連続したループ反復間でデータ共有を示す OpenMP* アプリケーションを実行するハードウェア構成について考えてみます。KMP_AFFINITY=compact を指定した際に行われるように、通信オーバーヘッド、キャッシュラインの無効オーバーヘッド、ページ・スラッシングが最小限になるように連続したスレッドを隣接してバインドさせます。ここで、利用可能な OpenMP* スレッドを活用していないアプリケーションに多くの並列領域があるとします。通常、スレッドは、同じコアにある別のアクティブなスレッドとの間にリソースの競合がない場合に実行速度が速くなるため、他のコアを使用せずに複数のスレッドを同じコアにバインドする状態は避けたほうが良いでしょう。通常、スレッドは、同じコアにある別のアクティブなスレッドとの間にリソースの競合がない場合に実行速度が速くなるため、他のコアを使用せずに複数のスレッドを同じコアにバインドする状態は避けたほうが良いでしょう。次の図は、KMP_AFFINITY=granularity=fine,compact,1,0 を設定してこの方法を示したものです。
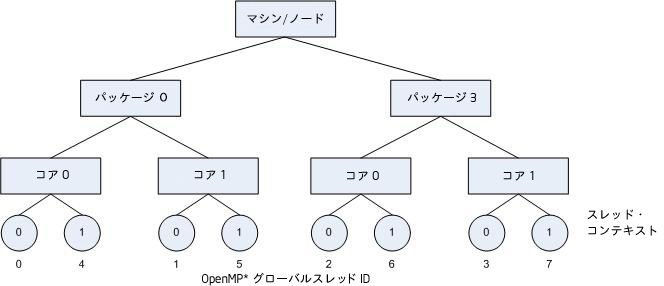
OpenMP* スレッド n+1 は、別のコアの OpenMP* スレッド n にできるだけ近いスレッド・コンテキストにバインドされます。いったん、それぞれのコアに 1 つの OpenMP* スレッドが割り当てられると、後続の OpenMP* スレッドは利用可能なコアに同じ順番で異なるスレッド・コンテキストに割り当てられます。
アフィニティー・タイプの修飾子の値
タイプの前に付ける修飾子はオプションです。修飾子を指定しない場合は、noverbose、respect、granularity=core が自動で使用されます。
修飾子は、左から右の順に解釈され、互いに無効にすることができます。例えば、KMP_AFFINITY=verbose,noverbose,scatter は、KMP_AFFINITY=noverbose,scatter または単に KMP_AFFINITY=scatter を指定するのと同じです。
modifier = noverbose (デフォルト)
詳細なメッセージは出力しません。
modifier = verbose
サポートされるアフィニティーに関するメッセージを出力します。メッセージには、パッケージ数、各パッケージにあるコア数、各コアにあるスレッド・コンテキスト数、物理スレッド・コンテキストにバインドされた OpenMP* スレッドについての情報が含まれます。
物理スレッド・コンテキストにバインドされた OpenMP* スレッドについての情報は、ハードウェア・スレッド・コンテキストとオペレーティング・システム (OS) プロセッサー (proc) ID 間のマッピングの形式で間接的に示されます。各 OpenMP* スレッドのアフィニティー・マスクは、OS プロセッサー ID セットとして出力されます。
例えば、インテル® ハイパースレッディング・テクノロジーを無効にした 2 つのプロセッサーを搭載したデュアルコア・システムで KMP_AFFINITY=verbose,scatter を指定すると、プログラムの実行時に次のようなメッセージが出力されます。
Verbose, scatter を指定した場合のメッセージ |
|---|
...
KMP_AFFINITY: Affinity capable, using global cpuid info
KMP_AFFINITY: Initial OS proc set respected:
{0,1,2,3}
KMP_AFFINITY: 4 available OS procs - Uniform topology of
KMP_AFFINITY: 2 packages x 2 cores/pkg x 1 threads/core (4 total cores)
KMP_AFFINITY: OS proc to physical thread map ([] => level not in map):
KMP_AFFINITY: OS proc 0 maps to package 0 core 0 [thread 0]
KMP_AFFINITY: OS proc 2 maps to package 0 core 1 [thread 0]
KMP_AFFINITY: OS proc 1 maps to package 3 core 0 [thread 0]
KMP_AFFINITY: OS proc 3 maps to package 3 core 1 [thread 0]
KMP_AFFINITY: Internal thread 0 bound to OS proc set {0}
KMP_AFFINITY: Internal thread 2 bound to OS proc set {2}
KMP_AFFINITY: Internal thread 3 bound to OS proc set {3}
KMP_AFFINITY: Internal thread 1 bound to OS proc set {1} |
verbose 修飾子を指定すると、いくつかの標準的、一般的なメッセージが生成されます。次の表は、メッセージの説明です。
メッセージ |
説明 |
|---|---|
"affinity capable (アフィニティー可)" |
すべてのコンポーネント (コンパイラー、オペレーティング・システム、ハードウェア) でスレッドのバインドが可能なようにアフィニティーがサポートされていることを示します。 |
"using global cpuid info (グローバル cpuid 情報使用)" |
スレッドを各オペレーティング・システムのプロセッサーにバインドし、cpuid 命令の出力をデコードすることにより、マシントポロジーが特定されたことを示します。 |
"using local cpuid info (ローカル cpuid 情報使用)" |
コンパイラーは初期スレッドのみから発行される cpuid 命令の出力をデコードし、マシントポロジーでオペレーティング・システムのプロセッサー数が使用されていることを想定しています。 |
"using /proc/cpuinfo (/proc/cpuinfo 使用)" |
Linux* のみ。cpuinfo がマシントポロジーを特定するのに使用されることを示します。 |
"using flat (flat 使用)" |
オペレーティング・システムのプロセッサー ID は、物理パッケージ ID と同じと見なされています。マシントポロジーを特定するこの方法は、その他の方法がどれも使用できず、また実際のマシントポロジーを正しく検出しない可能性がある場合に使用されます。 |
"uniform topology of (一様トポロジー)" |
マシントポロジーのマップは、どの階層においてもリーフがそろった完全なツリーです。 |
次に、オペレーティング・システムのプロセッサーからスレッド・コンテキスト ID へのマッピングが出力されます。OpenMP* スレッドのスレッド・コンテキスト ID へのバインドは、アフィニティー・タイプが none でない限り、次に出力されます。スレッドレベルは、角括弧の中に示されます (上のリストを参照)。これは、マシントポロジーのマップにはそのスレッド・コンテキスト・レベルが示されないことを意味します。詳細は、「マシントポロジーの特定」を参照してください。
modifier = granularity
OpenMP* スレッドを特定のパッケージやコアにバインドすると、インテル® ハイパースレッディング・テクノロジー (インテル® HT テクノロジー) 対応のインテル® プロセッサーを搭載したシステムでパフォーマンス・ゲインを期待できます。しかし、一般的に各 OpenMP* スレッドを特定のコアにある特定のスレッド・コンテキストにバインドしても効果は期待できません。粒度は、トポロジーマップ内で OpenMP* スレッドのフロートが許可される最下位レベルを示します。
この修飾子は、次の指定子をサポートします。
指定子 |
説明 |
|---|---|
core |
デフォルト。サポートされる最も荒い粒度レベルです。すべての OpenMP* スレッドが異なるスレッド・コンテキスト間でフロートするために、コアにバインドできます。 |
fine または thread |
最も細かい粒度レベルです。各 OpenMP* スレッドが 1 つのスレッド・コンテキストにバインドされます。この 2 つの指定子は、機能的に同じです。 |
2 つのプロセッサーを搭載したデュアルコア・システムで、インテル® ハイパースレッディング・テクノロジー (インテル® HT テクノロジー) が有効な場合に、KMP_AFFINITY=verbose,granularity=core,compact を指定すると、プログラムの実行時に次のようなメッセージが出力されます。
Verbose, granularity=core,compact を指定した場合のメッセージ |
|---|
KMP_AFFINITY: Affinity capable, using global cpuid info
KMP_AFFINITY: Initial OS proc set respected:
{0,1,2,3,4,5,6,7}
KMP_AFFINITY: 8 available OS procs - Uniform topology of
KMP_AFFINITY: 2 packages x 2 cores/pkg x 2 threads/core (4 total cores)
KMP_AFFINITY: OS proc to physical thread map ([] => level not in map):
KMP_AFFINITY: OS proc 0 maps to package 0 core 0 thread 0
KMP_AFFINITY: OS proc 4 maps to package 0 core 0 thread 1
KMP_AFFINITY: OS proc 2 maps to package 0 core 1 thread 0
KMP_AFFINITY: OS proc 6 maps to package 0 core 1 thread 1
KMP_AFFINITY: OS proc 1 maps to package 3 core 0 thread 0
KMP_AFFINITY: OS proc 5 maps to package 3 core 0 thread 1
KMP_AFFINITY: OS proc 3 maps to package 3 core 1 thread 0
KMP_AFFINITY: OS proc 7 maps to package 3 core 1 thread 1
KMP_AFFINITY: Internal thread 0 bound to OS proc set {0,4}
KMP_AFFINITY: Internal thread 1 bound to OS proc set {0,4}
KMP_AFFINITY: Internal thread 2 bound to OS proc set {2,6}
KMP_AFFINITY: Internal thread 3 bound to OS proc set {2,6}
KMP_AFFINITY: Internal thread 4 bound to OS proc set {1,5}
KMP_AFFINITY: Internal thread 5 bound to OS proc set {1,5}
KMP_AFFINITY: Internal thread 6 bound to OS proc set {3,7}
KMP_AFFINITY: Internal thread 7 bound to OS proc set {3,7} |
各 OpenMP* スレッドのアフィニティー・マスクは、OpenMP* スレッドがバインドされたオペレーティング・システムのプロセッサー・セットとしてリストされます (上を参照)。
次の図は、OpenMP* スレッドがバインドされた上記のリストのマシントポロジーを示しています。
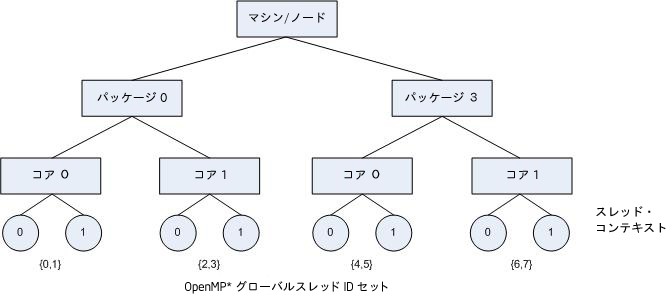
これに対し、KMP_AFFINITY=verbose,granularity=fine,compact または KMP_AFFINITY=verbose,granularity=thread,compact を指定すると、プログラムの実行時に各 OpenMP* スレッドが 1 つのハードウェア・スレッド・コンテキストにバインドされます。
Verbose, granularity=fine,compact を指定した場合のメッセージ |
|---|
KMP_AFFINITY: Affinity capable, using global cpuid info
KMP_AFFINITY: Initial OS proc set respected:
{0,1,2,3,4,5,6,7}
KMP_AFFINITY: 8 available OS procs - Uniform topology of
KMP_AFFINITY: 2 packages x 2 cores/pkg x 2 threads/core (4 total cores)
KMP_AFFINITY: OS proc to physical thread map ([] => level not in map):
KMP_AFFINITY: OS proc 0 maps to package 0 core 0 thread 0
KMP_AFFINITY: OS proc 4 maps to package 0 core 0 thread 1
KMP_AFFINITY: OS proc 2 maps to package 0 core 1 thread 0
KMP_AFFINITY: OS proc 6 maps to package 0 core 1 thread 1
KMP_AFFINITY: OS proc 1 maps to package 3 core 0 thread 0
KMP_AFFINITY: OS proc 5 maps to package 3 core 0 thread 1
KMP_AFFINITY: OS proc 3 maps to package 3 core 1 thread 0
KMP_AFFINITY: OS proc 7 maps to package 3 core 1 thread 1
KMP_AFFINITY: Internal thread 0 bound to OS proc set {0}
KMP_AFFINITY: Internal thread 1 bound to OS proc set {4}
KMP_AFFINITY: Internal thread 2 bound to OS proc set {2}
KMP_AFFINITY: Internal thread 3 bound to OS proc set {6}
KMP_AFFINITY: Internal thread 4 bound to OS proc set {1}
KMP_AFFINITY: Internal thread 5 bound to OS proc set {5}
KMP_AFFINITY: Internal thread 6 bound to OS proc set {3}
KMP_AFFINITY: Internal thread 7 bound to OS proc set {7} |
OpenMP* をハードウェア・コンテキストにバインドする例は、最初の例に示されています。
granularity=fine を指定すると、各 OpenMP* スレッドが 1 つの OS プロセッサーにバインドされます。これは、granularity=thread と等価で、現在、最も微細な粒度レベルです。
modifier = respect (デフォルト)
プロセスの元のアフィニティー・マスク、厳密には、OpenMP* ランタイム・ライブラリーを初期化するスレッドに指定されたアフィニティー・マスクが順守されます。動作は、Linux* と Windows* で異なります。
Windows*: プロセスの元のアフィニティー・マスクが順守されます。
Linux*: OpenMP* ランタイム・ライブラリーを初期化するスレッドのアフィニティー・マスクが順守されます。
前の例と同じ、インテル® ハイパースレッディング・テクノロジー (インテル® HT テクノロジー) が有効なシステムで、KMP_AFFINITY=verbose,compact を指定して、最初のアフィニティー・マスク {4,5,6,7} (各コアでスレッド・コンテキストは 1) を起動すると、コンパイラーでは、インテル® ハイパースレッディング・テクノロジー (インテル® HT テクノロジー) が無効の 2 つのプロセッサーを搭載したデュアルコアのマシンであると判断されます。
Verbose,compact を指定した場合のメッセージ |
|---|
KMP_AFFINITY: Affinity capable, using global cpuid info
KMP_AFFINITY: Initial OS proc set respected:
{4,5,6,7}
KMP_AFFINITY: 4 available OS procs - Uniform topology of
KMP_AFFINITY: 2 packages x 2 cores/pkg x 1 threads/core (4 total cores)
KMP_AFFINITY: OS proc to physical thread map ([] => level not in map):
KMP_AFFINITY: OS proc 4 maps to package 0 core 0 [thread 1]
KMP_AFFINITY: OS proc 6 maps to package 0 core 1 [thread 1]
KMP_AFFINITY: OS proc 5 maps to package 3 core 0 [thread 1]
KMP_AFFINITY: OS proc 7 maps to package 3 core 1 [thread 1]
KMP_AFFINITY: Internal thread 0 bound to OS proc set {4}
KMP_AFFINITY: Internal thread 1 bound to OS proc set {6}
KMP_AFFINITY: Internal thread 2 bound to OS proc set {5}
KMP_AFFINITY: Internal thread 3 bound to OS proc set {7}
KMP_AFFINITY: Internal thread 4 bound to OS proc set {4}
KMP_AFFINITY: Internal thread 5 bound to OS proc set {6}
KMP_AFFINITY: Internal thread 6 bound to OS proc set {5}
KMP_AFFINITY: Internal thread 7 bound to OS proc set {7} |
マシンには、8 個のスレッド・コンテキストがあるため、デフォルトではコンパイラーにより OpenMP* parallel 構造で 8 個のスレッドが作成されています。
"スレッド 1" の角括弧はスレッド・コンテキストのレベルが無視され、トポロジーマップには示されていないことを意味します。次の図は、対応するマシンのトポロジーマップです。
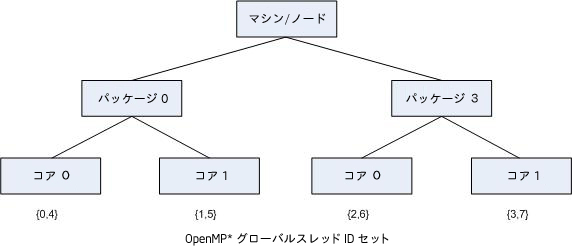
ローカルの cpuid 情報を使用してマシントポロジーを特定する場合、インテル® ハイパースレッディング・テクノロジー (インテル® HT テクノロジー) をサポートしていないマシンとサポートしているけれども無効になっているマシンとの区別がつきません。そのため、そのレベルの要素 (ノード) に兄弟がいない場合は、コンパイラーはそのレベルをマップに含めません (ただし、パッケージレベルは常に含まれます)。前述したように、パッケージレベルは、マシンに 1 つのパッケージしかない場合でも、常にトポロジーマップに表示されます。
modifier = norespect
プロセスのアフィニティー・マスクは順守されません。OpenMP* スレッドはすべてのオペレーティング・システムのプロセッサーにバインドされます。
physical と logical のみがアフィニティー・タイプとしてサポートされていた以前のバージョンの OpenMP* ランタイム・ライブラリーでは、norespect がデフォルトで、修飾子としては認識されませんでした。
compact と scatter がアフィニティー・タイプに追加されてから、デフォルトは respect に変更されました。そのため、アプリケーションが不完全な初期スレッド・アフィニティー・マスクを指定した状態では、logical と physical のスレッドのバインドは、新しいコンパイラー・バージョンで変更されることがあります。
modifier = nowarnings
アフィニティー・インターフェイスからの警告メッセージを出力しません。
modifier = warnings (デフォルト)
アフィニティー・インターフェイスからの警告メッセージを出力します (デフォルト)。
マシントポロジーの特定
IA-32 およびインテル® 64 アーキテクチャー・システムでは、パッケージに APIC (Advanced Programmable Interrupt Controller) がある場合、コンパイラーは cpuid 命令を使用して package id、core id、および thread context id を入手します。通常の状態では、システム上の各スレッド・コンテキストには起動時に固有の APIC ID が割り当てられます。コンパイラーは、OS スレッド・コンテキスト数 (マシン上のプロセシング要素の合計数) とともに cpuid 命令によって取得されるその他の情報を取得し、APIC ID から package ID、core ID、thread context ID を識別する方法を特定します。
cpuid 命令で APIC ID を指定する方法は 2 つあります - リーフ 4 で指定する以前の方法とリーフ 11 で指定するより新しい方法。リーフ 4 で利用可能な一意の APIC ID は 256 のみです。リーフ 11 ではそのような制限はありません。
通常、パッケージ上のすべての core id とコア上のすべての thread context id は連続しています。ただし、上の図で示されるように、package id の番号付けでは連続していないことも一般的です。
コンパイラーがいずれの方法を使用してもトポロジーを特定できないが、アフィニティーがオペレーティング・システムでサポートされている場合は、警告メッセージが出力され、トポロジーは flat と想定されます。例えば、ある flat トポロジーでは、オペレーティング・システムがプロセス N をパッケージ N にマップし、1 コアにつき 1 スレッドのみ、そして各パッケージには 1 コアがあると想定されます。
マシントポロジーが上記のように特定できない場合は、手動で /proc/cpuinfo を一時ファイルにコピーして、エラーを修正し、「KMP_CPUINFO_FILE と /proc/cpuinfo」のセクションで説明されているように、KMP_CPUINFO_FILE=<temp_filename> 環境変数を介して、マシントポロジーを OpenMP* ランタイム・ライブラリーに指定します。
マシントポロジーの特定に使用する方法にかかわらず、マシン上の各コアで 1 コアにつき 1 スレッドしかない場合は、スレッド・コンテキスト・レベルはトポロジーマップには表示されません。マシン上の各パッケージで 1 パッケージにつき 1 コアしかない場合は、コアレベルはトポロジーマップには表示されません。各パッケージには異なる数のコアが含まれている可能性があり、各コアは異なる数のスレッド・コンテキストをサポートしている可能性があるため、トポロジーマップは完全なツリー状とは限りません。
パッケージレベルは、マシンに 1 つのパッケージしかない場合でも、常にトポロジーマップに表示されます。
KMP_CPUINFO_FILE と /proc/cpuinfo
インテル® C++ コンパイラーの OpenMP* ランタイム・ライブラリーが Linux* システム上のマシントポロジーを検出する方法の 1 つに、/proc/cpuinfo の内容を解析する方法があります。このファイル (または Linux* ファイルシステムにマップされているデバイス) の内容が不十分であったり、エラーを含む場合は、内容を書き込み可能な一時ファイル <temp_file> にコピーし、修正するか必要な情報を追加して、さらに KMP_CPUINFO_FILE=<temp_file> を設定します。
これを行うことにより、OpenMP* ランタイム・ライブラリーは、/proc/cpuinfo に含まれる情報を読み取る代わりに、また APIC ID をデコードしてマシントポロジーを検出する代わりに、KMP_CPUINFO_FILE が示す <temp_file> を読み取ります。つまり、<temp_file> に含まれる情報が、その他の方法よりも優先されます。/proc/cpuinfo を持たない Windows* システムでは、KMP_CPUINFO_FILE インターフェイスを使用することができます。
/proc/cpuinfo または <temp_file> にはマシン上の各プロセシング要素のエントリーのリストが含まれています。各プロセッサー要素にはエントリー (分かりやすい名前と各行の値) のリストが含まれています。空白行は各プロセッサー要素を区切ります。次のフィールドのみが、<temp_file> または /proc/cpuinfo にある各エントリーからマシントポロジーを特定するのに使用されます。
フィールド |
説明 |
|---|---|
processor: |
プロセシング要素の OS ID を指定します。OS ID は一意でなければなりません。processor フィールドと physical id フィールドは、このインターフェイスの使用に唯一必須のものです。 |
physical id: |
物理チップ ID であるパッケージ ID を指定します。各パッケージには複数のコアが含まれています。パッケージレベルは常にインテル® コンパイラーの OpenMP* ランタイム・ライブラリーのマシン・トポロジー・モデルにあります。 |
core id: |
コア ID を指定します。コア ID がない場合は、デフォルトの 0 に設定されます。マシン上の各パッケージがシングルコアしかない場合は、(コア ID フィールドのいくつかが非ゼロの場合でも) コアレベルはマシンのトポロジーマップにはありません。 |
thread id: |
スレッド ID を指定します。コア ID がない場合は、デフォルトの 0 に設定されます。マシン上の各コアでシングルスレッドしかない場合は、(スレッド ID フィールドのいくつかが非ゼロの場合でも) スレッドレベルはマシンのトポロジーマップにはありません。 |
node_n id: |
これは、/proc/cpuinfo の拡張です。不均等メモリーアクセス (NUMA: Non-Uniform Memory Access) システムにおける異なるレベルのメモリー相互接続でノードを指定するのに使用できます。任意のレベル n がサポートされています。node_0 レベルがパッケージレベルに最も近いレベルで、複数のパッケージがレベル 0 で 1 つのノードを構成します。レベル 0 の複数のノードは、レベル 1 で 1 つのノードを構成します。 |
各エントリーは、示されているとおりに正確に小文字で、オプションのスペース、コロン (:)、さらにオプションのスペース、そして整数 ID を記述します。これ以外のフィールドは無視されます。
注
多くの Linux* バリアントで thread id フィールドが /proc/cpuinfo に含まれておらず、siblings とラベル付けされたフィールドがノードごとのスレッド数またはパッケージごとのノード数を指定することはよくあることことです。ただし、インテルの OpenMP* ランタイム・ライブラリーは、siblings とラベルされたフィールドを無視するため、thread id フィールドと siblings フィールドを区別できます。このような状況が発生した場合は、警告メッセージの「物理ノード/パッケージ/コア/スレッド ID が一意ではありません。」が表示されます (指定されたタイプが nowarnings の場合を除く)。
Windows* プロセッサー・グループ
64 ビットの Windows* オペレーティング・システムでは、複数のプロセッサー・グループが 64 を超えるプロセッサーに対応できます。各グループのサイズは、64 プロセッサーの最大値までに制限されます。
複数のプロセッサー・グループが検出されると、デフォルトでは 2 レベルのツリー (レベル 0 はグループ内のプロセッサー、レベル 1 は異なるグループ) であると判断されます。そして、グループにバインドされた OpenMP* スレッド数がグループ内のプロセッサー数と等しくなるまで、スレッドがグループに割り当てられ、後続のスレッドは次のグループに割り当てられます。
デフォルトでは、スレッドはグループ内のすべてのプロセッサー間を移動することができ、粒度はグループの数と同じになります [granularity=group]。このバインドを無効にし、compact、scatter など、別のアフィニティー・タイプを明示的に使用することができます。その場合は、スレッドが異なるグループの複数のプロセッサーにバインドされないように、十分に細かい粒度を使用する必要があります。
特定のマシン・トポロジー・モデル・メソッドの使用 (KMP_TOPOLOGY_METHOD)
KMP_TOPOLOGY_METHOD 環境変数を設定して、特定のマシン・トポロジー・モデル・メソッドを OpenMP* で使用するように強制できます。
値 |
説明 |
|---|---|
cpuid_leaf11 |
cpuid 命令のリーフ 11 により指定された APIC ID をデコードします。 |
cpuid_leaf4 |
cpuid 命令のリーフ 4 により指定された APIC ID をデコードします。 |
cpuinfo |
KMP_CPUINFO_FILE を指定しない場合は、/proc/cpuinfo を解析してトポロジーを特定するように強制できます (Linux* のみ)。 前述のように、KMP_CPUINFO_FILE を指定する場合は、それを使用します (Windows* または Linux*)。 |
group |
2 レベルのマップ (レベル 0 はグループ内の異なるプロセッサーを指定、レベル 1 は異なるグループを指定) として判断します (64 ビットの Windows* のみ)。 |
flat |
プロセッサーの flat (線形) リストとして判断します。 |
hwloc |
Portable Hardware Locality (hwloc) ライブラリーと同様に判断します。最も詳細なモデルで、NUMA ノード、パッケージ、コア、ハードウェア・スレッド、キャッシュ、Windows* プロセッサー・グループなどを含みます。 |
OS プロセッサー ID (GOMP_CPU_AFFINITY) を明示的に指定する
注
GOMP_CPU_AFFINITY 環境変数は、後述の「低レベルのアフィニティー API」で説明されているように、最初の並列領域の前、または omp_get_max_threads()、omp_get_num_procs()、アフィニティー API 呼び出しを含む特定の API 呼び出しの前に設定する必要があります。
ライブラリーにハードウェア・トポロジーを検出させて自動的に OpenMP* スレッドをプロセシング要素に割り当てる代わりに、オペレーティング・システム (OS) プロセッサー (proc) ID のリストを使用して、明示的に割り当てを指定することができます。ただし、これには OS proc ID がどのプロセシング要素を表現しているかについての知識が必要です。
このリストは、KMP_AFFINITY 環境変数に明示的なアフィニティー・タイプとともに proclist 修飾子で指定されるか、またはインテルの OpenMP* 互換ライブラリーの使用時に、GOMP_AFFINITY 環境変数 (gcc との互換用) で指定されるかのいずれかです。
-qopenmp-lib compat コンパイラー・オプションで有効にされたインテルの OpenMP* 互換ライブラリーを使用する際、Linux* システムでは GOMP_AFFINITY 環境変数を使用して OS プロセッサー ID を指定します。その構文は、libgomp のものと同じです (<proc_list> が GOMP_AFFINITY 環境文字列全体を生成すると想定)。
値 |
説明 |
|---|---|
<proc_list> := |
<entry> | <elem> , <list> | <elem> <whitespace> <list> |
<elem> := |
<proc_spec> | <range> |
<proc_spec> := |
<proc_id> |
<range> := |
<proc_id> - <proc_id> | <proc_id> - <proc_id> : <int> |
<proc_id> := |
<positive_int> |
このリストに指定されている OS プロセッサーは、その後 OpenMP* グローバルスレッド ID の順に OpenMP* スレッドに割り当てられます。リストにある要素よりも多くの OpenMP* スレッドが作成された場合は、リストサイズを基にする割り当てが行われます。つまり、OpenMP* グローバルスレッド ID n は、リスト要素 n mod <list_size> にバインドされます。
前の図の例と同じように OS proc ID が割り当てられた前述のマシン、インテル® ハイパースレッディング・テクノロジー (インテル® HT テクノロジー) が有効になっていないデュアルコア、デュアルパッケージ・マシンについて考えてみましょう。アプリケーションが 4 (デフォルト) ではなく、マシンを超過してしまう 6 つの OpenMP* スレッドを生成するとします。GOMP_AFFINITY=3,0-2 の場合、次の図に示されているように、gcc でコンパイルして、libgomp でリンクしたときと同じように OpenMP* スレッドがバインドされます。
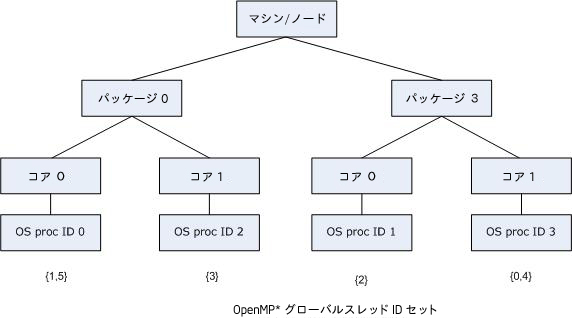
同じ構文が、OS proc ID リストを KMP_AFFINITY 環境変数文字列の proclist=[<proc_list>] 修飾子に指定するのに使用できます。若干の差異として、gcc の OpenMP* ランタイム・ライブラリー libgomp と全く同じセマンティクスを持つために、GOMP_AFFINITY 環境変数は granularity=fine を示唆します。KMP_AFFINITY 環境変数で granularity= 指定子を使用せずに OS proc リストを指定すると、デフォルトの granularity は変更されません。つまり、OpenMP* スレッドはシングルコアの異なるスレッド・コンテキスト間でフロートすることができます。このように、GOMP_AFFINITY=<proc_list> は、KMP_AFFINITY="granularity=fine,proclist=[<proc_list>],explicit" のエイリアスです。
KMP_AFFINITY 環境変数文字列では、構文はオペレーティング・システムのプロセッサー ID セットを処理するために拡張されます。ユーザーは OpenMP* スレッドが実行 ("フロート") できるオペレーティング・システムのプロセッサー ID セットを角括弧で指定できます。
値 |
説明 |
|---|---|
<proc_list> := |
<proc_id> | { <float_list> } |
<float_list> := |
<proc_id> | <proc_id> , <float_list> |
これにより、機能的には granularity= specifier と同様で、より柔軟性を発揮します。OpenMP* スレッドが実行される OS プロセッサーには、マシントポロジーで隣接している OS プロセッサーは除外されますが、その他の離れた OS プロセッサーは含まれます。次の図に示すように KMP_AFFINITY="granularity=fine,proclist=[3,0,{1,2},{1,2}],explicit" を使用して、OS プロセッサー 1 と OS プロセッサー 2 の間で OpenMP* スレッド 2 と 3 を "フロート" させることができます。
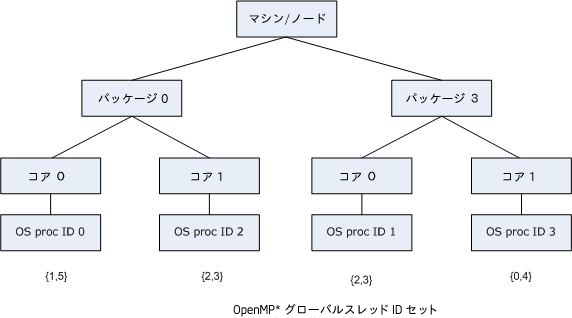
verbose も指定された場合、アプリケーションが実行された出力結果には以下が含まれます。
KMP_AFFINITY="granularity=verbose,fine,proclist=[3,0,{1,2},{1,2}],explicit" |
|---|
KMP_AFFINITY: Affinity capable, using global cpuid info
KMP_AFFINITY: Initial OS proc set respected: {0,1,2,3}
KMP_AFFINITY: 4 available OS procs - Uniform topology of
KMP_AFFINITY: 2 packages x 2 cores/pkg x 1 threads/core (4 total cores)
KMP_AFFINITY: OS proc to physical thread map ([] => level not in map):
KMP_AFFINITY: OS proc 0 maps to package 0 core 0 [thread 0]
KMP_AFFINITY: OS proc 2 maps to package 0 core 1 [thread 0]
KMP_AFFINITY: OS proc 1 maps to package 3 core 0 [thread 0]
KMP_AFFINITY: OS proc 3 maps to package 3 core 1 [thread 0]
KMP_AFFINITY: Internal thread 0 bound to OS proc set {3}
KMP_AFFINITY: Internal thread 1 bound to OS proc set {0}
KMP_AFFINITY: Internal thread 2 bound to OS proc set {1,2}
KMP_AFFINITY: Internal thread 3 bound to OS proc set {1,2}
KMP_AFFINITY: Internal thread 4 bound to OS proc set {3}
KMP_AFFINITY: Internal thread 5 bound to OS proc set {0}} |
低レベルのアフィニティー API
ユーザーがプログラムの実行開始前に環境変数を設定して (または並列領域に到達する前に kmp_settings インターフェイスを使用して) OpenMP* スレッドを OS proc にバインドさせなくても、それぞれの OpenMP* スレッドでは、実行し、kmp_set_affinity API 呼び出しでバインドさせる適切な OS proc セットを決定できます。
注意
このアフィニティー・インターフェイスを使用することで、スレッドを実行するハードウェア・リソースを完全に制御することができます。そのためには、論理 CPU (OS によって制御されるハードウェア・スレッドの列挙子) がどのように実行マシンの物理ハードウェアへマップされるかを詳しく理解する必要があります。マップ方法はマシンによって異なるため、マシン固有の情報をコードに記述すると、別のマシンで実行するときに不適切なアフィニティーを強制することになります。この詳細レベルで最適化を検討している場合、コードを別のマシンに移動する可能性が高いでしょう。
このインターフェイスを使用することで、MPI などのプログラムの起動メカニズムによって設定されるリソースの制約も無視できます。特に、同じノード上の複数の OpenMP* プロセスが同じハードウェア・スレッドを使用しないようにできます。これも、パフォーマンスの低下を引き起こすアフィニティーを強制する可能性があります。OpenMP* ランタイムはこの問題の発生を防ぐことも、問題が発生した際に警告を出力することもしません。このインターフェイスはエキスパート向けです。注意して使用してください。
移植性に優れ、低レベルの知識を必要としない、できるだけ高いレベルのアフィニティー設定を利用することを推奨します。
タイプ名 kmp_affinity_mask_t が omp.h で定義される C/C++ API インターフェイス:
注
これらのインターフェイスの一部には、同等のオフロード・インターフェイスがあります。同等のオフロード・インターフェイスには、ターゲットの種類と番号を指定する 2 つの追加の引数があります。詳細は、「CPU の関数を呼び出してコプロセッサーの実行環境を変更する」を参照してください。
構文 |
説明 |
|---|---|
int kmp_set_affinity (kmp_affinity_mask_t *mask) |
現在の OpenMP* スレッドのアフィニティー・マスクを *mask に設定します。ここで、*mask は以下にリストされた API 呼び出しで作成された OS proc ID のセットで、スレッドは、そのセットの OS proc でのみ実行します。成功した場合はゼロ (0)、エラーコードの場合は非ゼロを返します。 |
int kmp_get_affinity (kmp_affinity_mask_t *mask) |
現在の OpenMP* スレッドのアフィニティー・マスクを取得し、kmp_create_affinity_mask() への呼び出しで前もって初期化されているはずの *mask に格納します。成功した場合はゼロ (0)、エラーコードの場合は非ゼロを返します。 |
int kmp_get_affinity_max_proc (void) |
マシン上の最大 OS proc ID に 1 を足した値が返されます。すべての OS proc ID が 0 (包括的) と kmp_get_affinity_max_proc() (排他的) の間で保証されます。 |
void kmp_create_affinity_mask (kmp_affinity_mask_t *mask) |
新しい OpenMP* スレッド・アフィニティー・マスクを割り当て、*mask を OS proc の空のセットに初期化します。セット自身として、実際のセットへのポインターとして、またはセットを示すテーブルへのインデックスとしてなど、kmp_affinity_mask_kind のオブジェクトの使用は自由です。実際の表現が何であるかといった仮定をしてはなりません。 |
void kmp_destroy_affinity_mask (kmp_affinity_mask_t *mask) |
OpenMP* スレッド・アフィニティー・マスクの割り当てを解除するkmp_create_affinity_mask() への各呼び出しで、対応する kmp_destroy_affinity_mask() への呼び出しがなければなりません。 |
int kmp_set_affinity_mask_proc (int proc, kmp_affinity_mask_t *mask) |
OS proc ID proc をセット *mask に追加します (追加されていない場合)。成功した場合はゼロ (0)、エラーコードの場合は非ゼロを返します。 |
int kmp_unset_affinity_mask_proc (int proc, kmp_affinity_mask_t *mask) |
OS proc ID proc がセット *mask にある場合、それを削除します。成功した場合はゼロ (0)、エラーコードの場合は非ゼロを返します。 |
int kmp_get_affinity_mask_proc (int proc, kmp_affinity_mask_t *mask) |
OS proc ID proc がセット *mask にある場合は 1 を返します。ない場合は、0 を返します。 |
OpenMP* スレッドが kmp_set_affinity() への呼び出しに成功して自身のアフィニティー・マスクを設定したら、後続の kmp_set_affinity() への呼び出しでリセットされない限り、少なくとも並列領域が終わるまでは、そのスレッドは対応する OS proc セットにバインドされたままです。
並列領域間では、アフィニティー・マスク (および OS proc バインド機能に対応する OpenMP* スレッド) はスレッド・プライベートのデータ・オブジェクトと見なされ、「OpenMP* アプリケーション・プログラム・インターフェイス」で説明されているように、同様の永続性を持ちます。詳細は、OpenMP* API 仕様 (http://www.openmp.org) を参照してください。該当部分の一部を以下に抜粋 (参考訳) します。
アフィニティー・マスクとスレッドバインド機能が 2 つの連続したアクティブな並列領域間で永続するには、次の 3 つの条件がすべて満たされなければなりません。
別の明示的な並列領域の内側に入れ子構造の並列領域がないこと。
両方の並列領域の実行に使用されているスレッド数が同じであること。
囲まれたタスク領域にある dyn-var 内部制御変数の値が、両方の並列領域の入口で false であること。」
そのため、プログラムの実行が上記の OpenMP* 仕様の 3 つの規則に従っており、唯一の目的が各スレッドのアフィニティー・マスクを設定することであるプログラムの開始時点で並列領域を作成すると、低レベルのアフィニティー API 呼び出しにより、ユーザーは KMP_AFFINITY 環境変数の動作と同じことができます。
次に、低レベルのインターフェイスの使用例を示します。このコードは、実行スレッドを特定の論理 CPU にバインドします。
例 |
|---|
|
このプログラムは、OS proc ID のターゲットマシンの物理プロセシング要素へのマッピングに関する知識に基づいて記述されたものです。別のマシンや異なる OS がインストールされている場合、プログラムは実行されますが、OpenMP* スレッドの物理プロセシング要素へのバインド動作は異なります。また、明示的に効率の悪い分配を強制してしまう可能性があります。