インテル® アドバンスト・ベクトル・エクステンション (インテル® AVX) 組込み関数は、インテル® AVX 命令およびその他の 128 ビットの SIMD (Single Instruction, Multiple Data) 拡張命令に直接対応付けられます。インテル® AVX 命令は、既存のインテル® ストリーミング SIMD 拡張命令 (インテル® SSE) のインテル® 64 アーキテクチャー用ベクトル命令とインテル® ストリーミング SIMD 拡張命令 2 (インテル® SSE2) の倍精度浮動小数点組込み関数に似ています。ただし、インテル® AVX には、次の点が追加されています。
- 256 ビットのベクトルと SIMD レジスターセットのサポート
- 3 つおよび 4 つのオペランドをサポートする命令構文。新しい拡張命令を使用したプログラミングの柔軟性と効率性を向上させます。
- 既存の 128 ビットの SIMD 拡張命令の拡張。オペランドが 3 つの構文をサポートし、コンパイラーによる高水準言語表現のベクトル化を簡略化します。
- 新しいプリフィクス (VEX) を使用する命令のエンコード形式。オペランドが 3 つの構文、ベクトル長、既存の SIMD プリフィクスと REX 機能のコンパクションを簡単かつ効率的にエンコードします。
- インテル® AVX のデータ型は、バイトを使用する場合、最大 32 要素を 1 つのレジスターにパックできます。要素の数は、要素の型によって異なります (例: 8 つの単精度浮動小数点型または 4 つの倍精度浮動小数点型)。
インテル® AVX レジスター
インテル® AVX では、16 個のレジスター (YMM0-YMM15) が追加されています。各レジスターは 256 ビットで、16 個の SIMD (XMM0-XMM15) レジスターにエイリアスされています。インテル® AVX の新しい命令は、YMM レジスターのデータを操作します。インテル® AVX は、1 つの命令で最大 3 つのソースと 1 つのデスティネーションをエンコードする新しい方法を定義して、YMM レジスターのデータを操作するために一部の既存の命令を拡張しています。
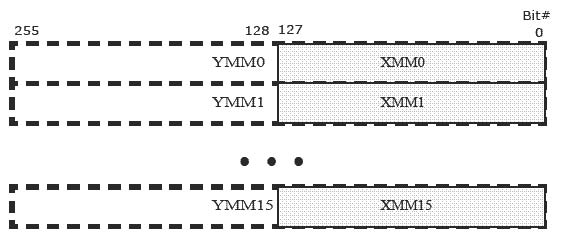
各レジスターは複数のデータ要素を保持できるため、プロセッサーは複数のデータ要素を同時に処理できます。このような処理方法は、SIMD (Single Instruction Multiple Data) 処理と呼ばれます。
新しい拡張命令セットのそれぞれの計算命令とデータ操作命令について、その命令を直接実装する C 組込み関数が用意されています。これにより、プログラマーは、レジスターの管理とアセンブリー言語のプログラミングを行う必要がなくなります。また、コンパイラーは、命令のスケジュールを最適化して、実行ファイルの処理速度を上げることができます。
インテル® AVX 型
インテル® AVX 組込み関数は、3 つの新しい C データ型をオペランドとして使用します。3 つのデータ型は、組込み関数に対するオペランドとして使用される新しいレジスターを表しています。__m256、__m256d、__m256i のデータ型があります。
__m256 データ型は、インテル® AVX 組込み関数で使用される拡張 SSE レジスター (YMM レジスター) の内容を表します。__m256 データ型は、8 つの 32 ビット倍精度浮動小数点値を保持できます。
__m256d データ型は、4 つの 64 ビット倍精度浮動小数点値を保持できます。
__m256i データ型は、32 個の 8 ビット整数値、16 個の 16 ビット整数値、8 個の 32 ビット整数値、または 4 個の 64 ビット整数値を保持できます。
コンパイラーは、__m256、__m256d、および __m256i 型のローカルデータとグローバルデータのアライメントを、スタック上の 32 バイト境界に合わせます。integer 型、float 型、または double 型の配列のアライメントを合わせるには、__declspec(align) 文を使用します。
インテル® AVX 組込み関数は、一部の操作でインテル® SSE2 の __m128、__m128d、および __m128i に似たデータ型も使用します。詳細は、「組込み関数の詳細」を参照してください。
インテル® AVX の VEX プリフィクス命令エンコードのサポート
インテル® AVX では、インテル® 64 および IA-32 命令エンコード形式の新しいプリフィクス、VEX が採用されています。VEX プリフィクスを使用する命令エンコードでは、いくつかの機能を提供します。
- VEX プリフィクス内のレジスターオペランドの直接エンコード
- 128 ビットおよび 256 ビット・レジスター・セットで処理される命令構文の効率的なエンコード
- REX プリフィクス機能のコンパクション
- SIMD プリフィクス機能のコンパクションとエスケープバイトのエンコード
- SIMD プリフィクスを使用してエンコードされた命令と比較して、メモリーオペランドを使用するほとんどの VEX エンコードの SIMD 数値/データ処理命令セマンティクスでメモリー・アライメント要件を緩和
VEX プリフィクス・エンコードは、YMM レジスター、XMM レジスター、そして時にはオペランドの 1 つとして汎用レジスターで処理される SIMD 命令に適用されます。VEX プリフィクスは、MMX レジスターまたは x87 レジスターで処理される命令ではサポートされていません。
インテル® AVX 組込み関数は、対応するが命令が VEX プリフィクスでエンコードされている[Q]xAVX オプションとともに使用することを推奨します。[Q]xAVX オプションでは、ほかのパックド命令も VEX でエンコードされます。その結果、インテル® AVX からインテル® SSE レガシーコードへの移行によるパフォーマンス・ストールの回数が少なくなります。
命名と使用する構文
ほとんどのインテル® AVX の組込み関数名は、次の表記規則に従います。
_mm256_<intrin_op>_<suffix>(<data type> <parameter1>, <data type> <parameter2>, <data type> <parameter3>)
次の表は、構文の各項目について説明したものです。
| _mm256, _mm128 | プリフィクスは結果のサイズを表します。通常はインテル® AVX ベクトルレジスターのサイズである 256 ビットですが、一部の比較および変換組込み関数では 128 ビットになります。 |
| <intrin_op> | 組込み関数の基本操作を示します。例えば、加算の場合は add、減算の場合は sub になります。 |
| <suffix> | 命令の操作対象となるデータの型を示します。各サフィックスの最初の 1 文字または 2 文字は、データがパックドデータ (p)、拡張パックドデータ (ep)、またはスカラーデータ (s) であることを示します。その他の文字は、次のデータ型を示します。
|
| <data type> | 引数のデータ型: __m256、 __m256d、 __m256i、 __m128、 __m128d、 __m128i、 const、 int、など。 |
| <parameter1> | 1 つ目のソース・ベクトル・レジスター: m1/s1/a |
| <parameter2> | 2 つ目のソース・ベクトル・レジスター: m2/s2/b |
| <parameter3> | 整数値: mask/select/offset 3 つ目の引数のビットは、組込み関数が操作を実行する条件を示します。 |
使用例
extern __m256d _mm256_add_pd(__m256d m1, __m256d m2);説明:
- add
- 加算が実行されることを示します。
- pd
- パックド倍精度浮動小数点値を示します。
パックされた値は、右から左の順序で表し、最下位の値がスカラー操作に使用されます。次の例について考えてみます。
double a[4] = {1.0, 2.0, 3.0, 4.0};
__m256d t = _mm256_load_pd(a);
次の結果が得られます。
__m256d t = _mm256_set_pd(4.0, 3.0, 2.0, 1.0);
つまり、値 t を保持する YMM レジスターは、次のようになります。

"スカラー" 要素は 1.0 です。一部の組込み関数では、命令の性質上、引数として即値 (定数整数) を指定しなければなりません。