インテル® Cilk™ Plus は古い機能 (非推奨) です。代わりに、OpenMP* またはインテル® TBB を使用してください。詳細は、「インテル® Cilk™ Plus の代わりに OpenMP* またはインテル® TBB を使用するためのアプリケーションの移行」を参照してください。
キーワードの記述方法は _Cilk_for です。ヘッダーファイル <cilk/cilk.h> には別の記述方法 (cilk_for) を利用するためのマクロが定義されています。ここでは、cilk.h で定義されている簡易版を使用します。
cilk_for 文は、指定した通常の C/C++ の for ループを置き換えて、ループの各反復を並列で処理することを指示します。
一般的な cilk_for 構文は、次のとおりです。
cilk_for (宣言と初期化;
条件式;
インクリメント式)
本体cilk_for 文には次の規則が適用されます。
宣言では、ループ制御変数を 1 つ初期化しなければなりません。C++ では、変数を cilk_for 文の前ではなく、cilk_for 文で宣言する必要があります (C ではこの限りではありません)。コンストラクターの構文の形式は重要ではありません。変数型がデフォルト・コンストラクターならば、明示的な初期値は必要ありません。
- 条件式では、次のいずれかの比較演算子を使用して、"終了式" のループ制御変数を比較しなければなりません:
- <
- <=
- !=
- >=
- >
終了式とループ制御変数は、比較演算子の左右どちらに置くこともできますが、ループ制御変数を終了式の中に記述することはできません。また、終了式の値はどの反復でも同じでなければなりません。
インクリメント式は、サポートされている次のいずれかの演算子を使用して、ループ制御変数の値を加算または減算します。
- +=
- -=
- ++ (プリフィクスまたはポストフィックス)
- -- (プリフィクスまたはポストフィックス)
ループの終了式と同様に、ループ制御変数に加算される値 (または減算される値) はどの反復でも同じでなければなりません。
- cilk_for ループの本体は並列に実行されるため、ループ本体でループ制御変数を変更してはなりません。
以下に、cilk_for ループの例をいくつか示します。
cilk_for (int i = begin; i < end; i += 2)
f(i);
cilk_for (T::iterator i(vec.begin()); i != vec.end(); ++i)
g(i);
C では、次のようにループ制御変数の宣言をループ前に記述できます (C++ ではこの限りではありません)。
int i;
cilk_for (i = begin; i < end; i += 2)
f(i);
cilk_for は、simd プラグマや _Simd キーワードによるベクトル化と互換性があります。
#pragma simd
cilk_for (int i = 0; i < N; ++i) {
// ループ本体
}
cilk_for _Simd (int i = 0; i < N; ++i) {
// ループ本体
}
cilk_for と _Simd や simd プラグマの組み合わせは、並列ループ内に入れ子された SIMD ループのように動作します。外側のループは (コンパイラーとランタイムシステムによって選択されたチャンクサイズで) チャンクを並列に実行し、内側のループはベクトル化により 1 つのチャンクを同時に処理します。cilk_for と SIMD ベクトル化を併用する場合、両方のすべての制約事項に従う必要があります。ベクトル化はワークをチャンクに分割し、左から右へ処理します。並列/ベクトルコードの組み合わせがチャンクを同じ順序で実行する可能性は低いですが、それぞれのコードが正しく動作できるように、両方の制約事項の共通部分に注意する必要があります。
最適な結果を得るためには、cilk_for と SIMD ベクトル化は、ワーク量が多い場合 (反復回数が多い場合または 1 反復あたりのワーク量が多い場合) にのみ併用すべきです。一般に、入れ子構造のループでは、最内ループのみベクトル化し、最も外側の 1 つまたは 2 つのループのみ cilk_for で並列化すると良いでしょう。ループの入れ子がこれよりも深い場合は、一般に中間の入れ子レベルはシリアルにすべきです。並列/ベクトル処理を組み合わせたループは、最外ループと最内ループが同じループの場合 (つまり、入れ子されていない場合) のみ使用するようにします。併用すべきかどうかテストする最適な方法は、ループを並列処理あり/なしでテストし、プロファイラーでそれぞれのパフォーマンスを評価します。
シリアル化されたインテル® Cilk™ Plus プログラムは、C/C++ プログラムと同じように動作します。シリアル化は、cilk_for を通常の for ループに置き換えるのと同じ結果となります。そのため、cilk_for ループは有効な C/C++ の for ループでなければなりませんが、cilk_for ループには C/C++ の for ループと比べていくつかの制限があります。
cilk_for におけるシリアル/並列実行の構造
cilk_for を利用することと、各ループ反復をスポーンすることは同じではありません。実際、インテル® コンパイラーは、ループ本体を分割統治法による再帰呼び出し可能な関数に変換します。この手法は、非常に優れたパフォーマンスを実現できます。2 つの手法において、明確な DAG(Directed Acyclic Graph)の違いが見られます。
最初に反復 N が 8 で、粒度が 1 の場合の、cilk_for ループにおける DAG を考えてみましょう。図中の数値は、ストランドと呼ばれるシリアル実行を行う命令のシーケンスを示します。これらの数値は、どのループ反復が、どのストランドで実行されるかを示しています。
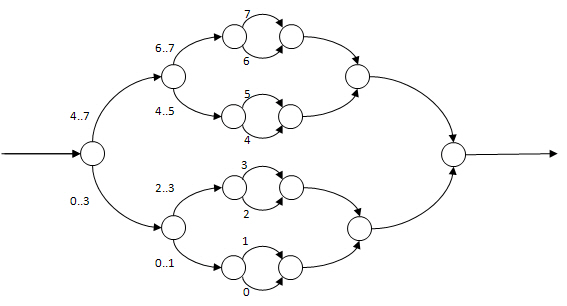
分割では、全体を半分にし、一方を子タスクが、残りを親タスクが継続して処理します。両方のループのオーバーヘッドと新たなタスクをスポーンするオーバーヘッドは、ループ本体のコストとともに均等に分割されることが重要です。
各ループ反復が同じ時間 T で実行されるなら、プログラムの始まりから終わりまでの最も時間のかかるパスは、8 回のループの場合 log2(N) * T もしくは 3 * T です。 ランタイムは、ループの反復数やワーカーの数にかかわらず、効率良くバランスをとります。
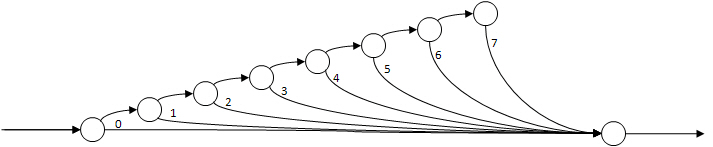
シリアルループ内でスポーンされた場合のシリアル/並列実行の構造
次に、シリアルループの各反復でスポーンを行った場合の DAG を示します。この場合、それぞれの子ストランドは 1 回のループ反復のみを処理するためワーカーの負荷は均等ではなく、同期に伴うスケジュールのオーバーヘッドを被ります。小さなループや、ループ本体が制御やスポーンのオーバーヘッドよりも時間を要する場合、パフォーマンスの差はほとんどないでしょう。ただし、ループが時間を要さない多くの反復で構成されている場合、オーバーヘッドのコストはいかなる並列化の利点をも打ち消すでしょう。
cilk_for の本体
cilk_for ループの本体は、cilk_for 文とその内側にある cilk_sync 文のスコープを制限する特別な領域を定義します。cilk_for 内の cilk_sync 文は、同じループ反復内でスポーンされた子ストランドの完了のみを待機します。ほかの反復と同期したり、周囲の関数の子ストランドと同期することはありません。また、ループの各反復の最後には (ブロック化された可変デストラクターが呼び出された後に) 暗黙的な cilk_sync があります。そのため、cilk_for ループに入るときに終了していない子がある場合、cilk_for ループを出るときに同じ子が実行されます。cilk_for ループ内でスポーンされた子はループが終了する前に同期され、逆に、ループに入る前に存在していた子ストランドはループ実行中に同期されることはありません。この cilk_for ループの性質は、非常に役立ちます (「例外処理」を参照)。
cilk_for ループ内で例外がスローされ同じ反復で例外が処理されなかった場合、いくつかの反復が実行されないことがあります。シリアル実行と違い、どの反復が実行され、どの反復が実行されないのかを完全には予測できません。例外をスローする場合を除いて、反復処理中はアボートできません。
Windows*: Microsoft* の構造化例外処理 (SEH) を使用する場合には (特に、/EHa コンパイラー・オプションと C/C++ の __try、__except、__finally、__leave 拡張では)、いくつかの制限があります。詳細は、「例外処理」の「Windows* 構造化例外処理」を参照してください。
cilk_for 型の要件
cilk_for ループの制御変数として C++ のカスタムデータ型を使用する場合は、注意が必要です。カスタムデータ型ごとに、ランタイムシステムがループのサイズを計算し、分割できるようにするためのメソッドを提供する必要があります。整数型や STL のランダムアクセス・イテレーターには、すでに必要な型が用意されているため、追加の作業は必要ありません。
制御変数が variable_type 型で宣言され、ループ終了式が termination_type 型で定義されている場合、次のようになります。
extern termination_type end; extern int incr; cilk_for (variable_type var; var != end; var += incr) ;
コンパイラーにループの実行回数を通知するため、いくつかの関数を用意しなければなりません。これらの関数を使用して、コンパイラーは variable_type 変数と termination_type 変数の差 (整数値) を計算します。
difference_type operator-(termination_type, variable_type);
difference_type operator-(variable_type, termination_type);
次の条件が適用されます。
引数の型は同じでなくてもかまいませんが、termination_type または variable_type から変換可能でなければなりません。
ループカウントが増える場合は 1 番目の operator- を使用し、ループカウントが減る場合は 2 番目の operator- を使用します。
引数は、定数参照または値で渡されます。
インクリメントがプラスかマイナスかによって、プログラムはランタイムに適切な関数を呼び出します。
difference_type の戻り値として任意の整数型を使用できますが、両方の関数で同じでなければなりません。
difference_type の符号の有無は重要ではありません。
また、次のように定義することで、システムに制御変数の加算方法を知らせる必要があります。
variable_type::operator+=(difference_type);
ループ中で += または ++ ではなく -= または -- を使用する場合は、operator+= の代わりに operator-= を定義します。
これらの演算子関数は、一般的な演算でなければなりません。コンパイラーは、1 を 2 回足すのは、2 を 1 回足すのと同じであると見なします。例えば、
X - Y == 10
の場合、次のことが仮定されます。
Y + 10 == X
cilk_for の制約
分割統治手法を使用してループを並列化するためには、コンパイラーはループの反復回数と各反復でのループ制御変数の値をあらかじめ計算する必要があります。そのため、ユーザー定義型であっても、制御変数の値は整数として加算、減算、比較できなければなりません。STL からの整数、ポインター、ランダムアクセス・イテレーターは、すべて整数として振る舞うためこの要件を満たしています。
また、cilk_for ループには、標準 C/C++ の for ループにはない次の制限があります。次の違反に対して、コンパイラーはエラーまたは警告を出力します。
ループ制御変数は 1 つでなければならず、初期化では必ず値を設定する必要があります。次の形式はサポートされていません。
cilk_for (unsigned int i, j = 42; j < 1;i++, j++)
ループ制御変数はループ本体で変更してはなりません。次の形式はサポートされていません。
cilk_for (unsigned int i = 1; i < 16;++i) i = f();
終了値とインクリメント値は、ループ開始されるときに 1 回だけ評価され、各反復では再評価されません。そのため、ループ本体内でこれらの値を変更しても反復が追加されたり、取り除かれることはありません。次の形式はサポートされていません。
cilk_for (unsigned int i = 1; i < x; ++i)x = f();
C++ では、制御変数は、ループの外側ではなく、ループのヘッダーで宣言する必要があります。次の形式は、C ではサポートされていますが、C++ ではサポートされていません。
int i; cilk_for (i = 0; i < 100;i++)
cilk_for ループの本体内に break 文や return 文は記述できません。コンパイラーは、エラーメッセージを生成します。
goto 文は、分岐先が同じループの本体内にある場合に cilk_for ループの本体内でのみ使用できます。goto 文を使用して cilk_for ループの本体外への移動が行われると、コンパイラーはエラーメッセージを生成します。同様に、goto 文を使用して、cilk_for ループの外側からループの本体内へ移動することはできません。
- cilk_for ループは、"ラップアラウンド" しません。例えば、C/C++ では次のように記述することができます: for (unsigned int i = 0; i != 1; i += 3);
C/C++ ループではこれは動作しますが、ループは 2,863,311,531 回実行 (反復) されます。このようなループを cilk_for ループに変換すると、予期できない結果をもたらします。
cilk_for ループは、次のような無限ループであってはなりません。
cilk_for (unsigned int i = 0; i != i; i += 0);
cilk_for の粒度
cilk_for 文は、ループを 1 つまたは複数の反復からなるチャンクに分割します。各チャンクはシリアル実行され、ループが実行される間チャンクはスポーンされることで並列に動作します。それぞれのチャンクの最大反復回数を粒度といいます。
反復回数の多いループでは、粒度が比較的大きくてもオーバーヘッドを大幅に減らすことができます。また、反復回数の少ないループでは、粒度を小さくすることでプログラムの並列性が高まり、プロセッサー・コア数の増加に伴ってパフォーマンスが向上します。
粒度の設定
cilk grainsize プラグマを使用して、プログラム中で cilk_for ループの粒度を指定することができます。
#pragma cilk grainsize = expression
例えば、次のように記述します。
#pragma cilk grainsize = 1
cilk_for (int i=0; i<IMAX; ++i) { . . . }
粒度を指定しない場合、ランタイムシステムが自動的に粒度を計算します。デフォルト値は、次のプラグマを指定した場合と同じになります。
#pragma cilk grainsize = min(2048, N / (8*p))
N はループの反復回数、p はプログラムの実行中に生成されるワーカーの数です。この式は、8 から 2048 までの並列化に対応します。反復回数の少ないループ (8 * ワーカーより少ない場合) では、粒度は 1 に設定され、各反復は並列に動作します。反復回数が (16484 * p) を超えるループでは、粒度は 2048 に設定されます。
cilk grainsize プラグマは、特に大きなループや反復ごとに作業量が大きく異なるループの粒度を小さくする (多くの場合は 1 まで) ために通常使用されます。粒度を小さくすると並列性が高まりロードバランスが向上しますが、スケジュールと関数呼び出しのオーバーヘッドが増加します。
cilk grainsize プラグマは粒度を大きくするために使用することもできます。特にループ本体が短い場合、オーバーヘッドが減少します。ただし、粒度が約 1000~2000 に達すると、反復あたりの作業量が非常に少ない場合でも、cilk_for のオーバーヘッドは重要でなくなります。この状態から、粒度をそれ以上大きくする利点はありません。実際、粒度が大きすぎると、並列性が低くなり、ロードバランスが適切に行われなくなります。一般に、より大きく、あまりバランスの取れていないループの反復では、粒度を小さくする必要があります。
粒度をゼロにした場合は、デフォルトの式が使用されます。粒度をゼロ未満にした場合の結果は不定です。
プラグマで指定された式はランタイムに評価されます。例えば、次のようにワーカー数に基づいて粒度を設定することもできます。
#pragma cilk grainsize = n/(4*__cilkrts_get_nworkers())
ランタイムのループ分割
実行されるチャンクの数は、反復回数 N を粒度 K で除算した結果とほぼ同じになります。
インテル® コンパイラーは、分割統治手法を再帰的に使用して、ループを実行します。制御構造を示す擬似コードは次のようになります。
void run_loop(first, last)
{
if (last - first) < grainsize)
{
for (int i=first; i<last ++i) LOOP_BODY;
}
else
{
int mid = (last+first)/2;
cilk_spawn run_loop(first, mid);
run_loop(mid, last);
}
}
つまり、残りのチャンクが粒度以下になるまで、ループは繰り返し 2 等分されます。通常、実際に各チャンクが実行する反復回数は粒度よりも小さくなります。
例えば、16 回反復する cilk_for について考えてみます。
cilk_for (int i=0; i<16; ++i) { ... }
粒度が 4 の場合、4 つのチャンクがそれぞれ 4 回ずつ反復を実行します。粒度を 5 に変更すると、4 つのチャンクは均等ではなくなり、それぞれ 5、3、5、3 回の反復を実行します。
アルゴリズムを詳しく見ると、同じ大きさの 16 回のループがあり、粒度が 2 と 3 の場合は、ともに 8 チャンクが 2 回ずつ反復を実行することが分かります。
最適な粒度の選択
通常は、デフォルトの粒度で適切に実行できます。ほかの値を選択する場合は、次のガイドラインに従ってください。
それぞれの反復で作業量が大きく異なり、作業量の大きい反復が均等に分配されない可能性がある場合は、粒度を小さくしてみるとよいでしょう。これにより、時間のかかるチャンクがほかのチャンクが終了した後も実行し続け、ほかのワーカーが処理すべき作業を持たないために、アイドル状態になる状況を減らすことができます。
それぞれの反復の作業量がほぼ同じで小さい場合は、粒度を大きくしてみるとよいでしょう。ただし、多くの場合、このようなケースではデフォルトの値が適切です。粒度を大きくすると、並列性を損なう恐れがあります。
粒度を変更する場合は、パフォーマンス・テストを行って、ループの実行速度が速くなること (遅くならないこと) を確認してください。