プロファイルに基づく最適化 (PGO) では、命令キャッシュの問題を軽減させるコードの再構成、コードサイズの減少、分岐予測ミスの減少などによりアプリケーション・パフォーマンスの向上を図ることができます。PGO を行うと、アプリケーションで最も頻繁に実行される領域に関する情報がコンパイラーに伝えられます。この領域を知ることで、コンパイラーは、より慎重かつ明確にアプリケーションの最適化を行います。
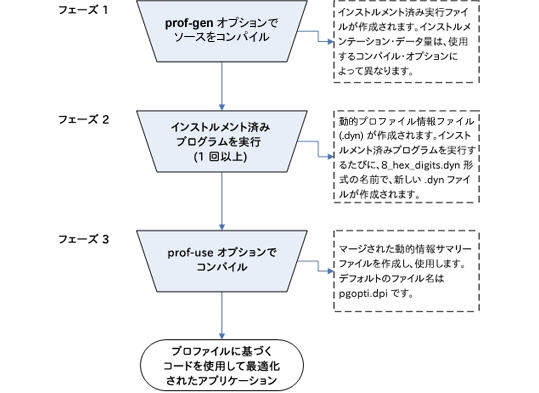
PGO には、3 つの基本フェーズ (ステップ) があります。
プログラムをインストルメントします。コンパイラーはソースコードおよび特別なコードからインストルメント済みプログラムを作成し、リンクします。
インストルメント済み実行ファイルを実行します。インストルメント済みコードが実行されるたびに、最終コンパイルで使用される動的情報ファイルが生成されます。
最終コンパイルを実行します。2 度目のコンパイルでは、生成した動的情報がマージされて 1 個のサマリーファイルができます。このプロファイル情報の概要を使用して、コンパイラーはプログラム内で最も頻繁に使用するパスの実行の最適化を図ります。
サポートされるオプションについては、「プロファイルに基づく最適化 (PGO) オプション」 を参照してください。また、コマンドラインからの PGO の使用の詳細については、「アプリケーションのプロファイル」を参照してください。
PGO には、次のような利点があります。
レジスター割り当てにプロファイル情報を使用して退避コードの場所を最適化します。
最も可能性の高い対象を識別することにより、間接関数呼び出しの分岐予測が向上します。一部のプロセッサーでは、その長いパイプラインにより、分岐予測が向上され、高いパフォーマンスが得られます。
実行の反復回数が少ないループを検出しベクトル化せず、ベクトル化により追加される可能性のあるランタイム・オーバーヘッドを減少させます。
プロシージャー間の最適化 (IPO) と PGO は互いに影響します。PGO を使用すると、コンパイラーは関数のインライン展開に関して的確な判断が下せる場合が多くなるため、プロシージャー間の最適化の効率が向上します。サイズや速度に注目する他の最適化と異なり、IPO および PGO の結果はばらつきます。このばらつきは、各プログラムが異なるプロファイルと異なる最適化の機会を持つという特性のために発生します。
PGO によるパフォーマンスの向上
PGO は、コンパイルの時点での予測が困難な、繰り返し実行される分岐を含むコードの最適化として最も有効に働きます。この例として、ほとんどの場合にエラー条件が偽になるようなエラーチェック処理を多数含むコードが挙げられます。このような、いわゆるほとんど実行されない (コールド) エラー処理コードを、分岐予測をほとんど誤ることのないように配置できます。頻繁に実行される (ホット) コードに対するコールドコードの挿入を最小限に抑えると、命令キャッシュの動作が改善されます。
PGO を使用する際は、次のガイドラインに従ってください。
インストルメント済みコードを実行してからフィードバック・コンパイルを行うまでの間は、プログラムに加える変更を最小限に抑えます。フィードバック・コンパイルでは、情報が生成した後に変更された関数の動的情報は無視します。プログラムを変更すると、PGO リマークが有効な場合、または PGO リマークが最適化レポートで見つかった場合、コンパイラーは動的情報が関数に対応していないことを示す警告を発行します。
インストルメント済みコードを実行してからフィードバック・コンパイルを行うまでの間にソースファイルに多数の変更を加える場合は、インストルメンテーション・コンパイルを繰り返します。
最も多く使用されているコードのセクションを識別します。プログラムに与えられるデータセットがほぼ一定で、何度実行しても同じような動作にしかならない場合、PGO でプログラム実行を最適化できます。
プログラムに与えられるデータセットが毎回異なり、異なるアルゴリズムが呼び出される場合もあります。このような場合、プログラムは実行のたびに違った動作になることがあります。コードの動作が実行ごとに大きく異なる場合、PGO を使用してもあまりメリットは得られません。アプリケーションのパフォーマンスを的確に特徴付けるのに複数のデータセットが必要な場合は、すべてのデータセットでアプリケーションを実行してから、動的プロファイルをマージします。これにより、アプリケーションが最適化されます。
プロファイル情報によって得られるメリットが、最新のプロファイルの維持に必要な労力に見合うものであるかどうか検討する必要があります。