I/O レコードは、論理的に関連付けられるデータ項目 (フィールド) の集合であり、1 つの単位として処理されます。レコード型とは、フィールドをレコードに格納するための規則を指します。
ファイル内のデータのレコード型は、ファイル属性としては保持されません。ファイルの作成時に指定したレコード型以外のレコード型を使用した場合、結果は不定です。
次の表に示すように、多くのレコード型があります。表には、それぞれのレコード・オーバーヘッドもリストされています。レコード・オーバーヘッドは、それぞれのレコードに関連付けられたファイルシステムによって内部で使用されるバイトのことです。レコードの読み取り中および書き込み中は使用できません。レコード・オーバーヘッドが分かっていると、アプリケーションの記憶域要件の概算を効率的に行えます。オーバーヘッド・バイトは記憶媒体にありますが、OPEN 文で RECL 指定子を使ってレコード長を指定するときには含めないでください。
レコード型 |
利用可能なファイル編成および移植に関する注意事項 |
レコード・オーバーヘッド |
|---|---|---|
固定長 |
相対ファイル編成またはシーケンシャル・ファイル編成。 |
シーケンシャル・ファイルの場合はなし。相対ファイルでは、vms オプションが省略された場合、または novms オプションが指定された場合はなし。vms オプションが指定された場合は 1 バイト。 |
可変長 |
シーケンシャル・ファイル編成のみ。可変長レコード型は、一般的にマルチベンダー・プラットフォーム間での移植性が最も高いレコード型です。 |
各レコードに 8 バイト。 |
セグメント |
シーケンシャル・アクセスを使用するシーケンシャル・ファイル編成のみ。セグメントレコード型は、インテル® Fortran 固有のレコード型なので、Fortran 以外の言語で書かれたプログラムを移植するときに使用してはなりません。また、インテル® Fortran が使用されていない場所でも使用してはなりません。ただし、セグメントファイル内の書式付きデータは、インテル® Fortran プラットフォーム間で移植することができます。 |
各レコードに 4 バイト。レコードサイズが奇数の場合は、1 つのパディングバイト (スペース) が追加されます。 |
Stream (レコード区切り文字なし) |
シーケンシャル・ファイル編成のみ。 |
必要なし。 |
Stream_CR (CR をレコード区切り文字として使用) |
シーケンシャル・ファイル編成のみ。 |
各レコードに 1 バイト。 |
Stream_LF (LF をレコード区切り文字として使用) |
シーケンシャル・ファイル編成のみ。 |
各レコードに 1 バイト。 |
Stream_CRLF (CR と LF をレコード区切り文字として使用) |
シーケンシャル・ファイル編成のみ。 |
各レコードに 2 バイト。 |
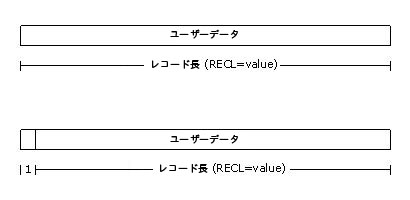
固定長レコード
固定長レコードを指定すると、ファイル内の全レコードのバイト数が同一になります。固定長レコードを格納するファイルを開くときには、RECL キーワードを使用し、レコード長を指定する必要があります。直接アクセスで開かれるシーケンシャル・ファイルには、ファイルのレコード位置を正確に計算できるように、固定長レコードが格納されていなければなりません。
相対編成ファイルの場合、固定長レコードの構成とオーバーヘッドは、ファイルを参照するプログラムが vms オプションを使用してコンパイルされたかどうかによって異なります。
vms オプションが省略された相対ファイルでは (デフォルト)、各レコードに制御情報は含まれません。
vms オプションが指定された相対ファイルでは、各レコードの先頭に 1 バイトの制御情報が含まれます。
次の図は、固定長レコードのレコード構成です。最初の図は、vms オプションが省略されたすべてのシーケンシャル・ファイルと相対ファイルです。2 番目の図は、vms オプションが指定された相対ファイルです。
可変長レコード
可変長レコードは、指定された最大レコード長まで任意のバイト数を含めることができ、シーケンシャル・ファイルにのみ適用されます。
可変長レコードの前後には、長さフィールドを含む 4 バイトの制御情報が追加されます。終端長さフィールドにより、BACKSPACE で効率的に前のレコードへ戻ることができます。各長さフィールドに格納された 4 バイトの整数値は、その可変長レコード中のデータバイト数 (オーバーヘッド・バイトを除く) を示します。
可変長レコードの文字カウントフィールドは、Q 書式記述子を指定して READ 文を発行することでレコードの読み取り時に知ることができます。その後、このカウントフィールドを使用し、I/O リストに何バイトが含まれているかを決定することができます。
次の図は、2GB 未満の可変長レコードのレコード構成です。

2,147,483,639 バイトよりも大きなレコード長では、レコードはサブレコードに分けられます。サブレコードの長さは、1 から 2,147,483,639 までです。
先頭長さフィールドの符号ビットは、後続のレコードがあるかないかを示します。終端長さフィールドの符号ビットは、前にサブレコードがあることを示します。符号ビットの位置は、ファイルのエンディアン形式により決定されます。
以下は、符号ビットの値に関する規則です。
後続のサブレコードには、符号ビット値が 1 の先頭長さフィールドがあります。
レコードを構成する最後のサブレコードには、符号値 0 の先頭長さフィールドがあります。
前にサブレコードがあるサブレコードには、符号ビット 1 の終端長さフィールドがあります。
レコードを構成する最初のサブレコードには、符号値 0 の終端長さフィールドがあります。
符号ビットの値が 1 の場合、レコード長は 2 の補数表現で格納されます。
次の図は、2GB を超える可変長レコードのレコード構成です。

通常、インテル® Fortran プログラムが可変長レコードを使用して書き出したファイルに、テキストファイルとしてアクセスすることはできません。可変長レコードを含むテキストファイルを出力する場合、代わりに Stream_LF レコード形式を使用してください。
セグメントレコード
セグメントレコードは、1 つのシーケンシャル編成ディスクファイル内の、1 つ以上の可変長書式なしレコードから構成される単一の論理レコードです。シーケンシャル・アクセスを使用してシーケンシャル編成ファイルに書き込まれた書式なしデータは、デフォルトではセグメントレコードとして保存されます。
セグメントレコードは、非常に長いレコードを書き込む際に、1 つの長い可変長レコードを定義できない、または定義したくない場合に便利です。例えば、仮想メモリーの制限によってプログラムが実行できないような場合です。より小さいセグメントレコードを使用すれば、プログラムを実行するシステム上の仮想メモリーの制限により問題が発生する可能性を減らすことができます。
ディスクファイルでは、セグメントレコードは 1 つまたは複数のセグメントで構成される単一の論理レコードです。各セグメントが 1 つの物理レコードです。セグメント (論理) レコードは、絶対最大レコード長 (21.4 億バイト) を超えることができますが、各セグメント (物理レコード) は、最大レコード長を超えることができません。
セグメントレコードを含む書式なしシーケンシャル・ファイルにアクセスするには、ファイルを開く際に FORM='UNFORMATTED' および RECORDTYPE='SEGMENTED' を指定します。
次の図に示すように、セグメントレコードは、4 バイトの制御情報と、その後のユーザーデータで構成されます。

制御情報は、2 バイトの整数型レコード長カウント (セグメント識別子に使用される 2 バイトを含む) と、その後の 2 バイトの整数型セグメント識別子で構成されます。セグメント識別子は、セグメントが次のいずれかを示します。
識別子の値 |
指定セグメント |
|---|---|
0 |
最初と最後のセグメントの間にあるいずれかのセグメント |
1 |
第 1 セグメント |
2 |
最終セグメント |
3 |
単独セグメント |
指定されたレコード長が奇数の場合、ユーザーデータには空白が 1 つ (1 バイト) パディングされますが、このバイトは 2 バイトの整数型レコード・サイズ・カウントには加算されません。
アプリケーションで、インテル® Fortran 以外の言語で記述されているプログラムやインテル® プラットフォーム用に記述されていないプログラムに対して同じファイルを使用しなければならない場合には、セグメントレコード型を使用しないでください。
ストリーム・ファイル・データ
ストリームファイルは、レコードにグループ化されず、制御情報を含まれません。ストリームファイルは CARRIAGECONTROL='NONE' とともに使用され、入力文または出力文で指定された変数の範囲でのみ、読み書きされる文字、あるいはバイナリーデータを格納します。
次の図は、ストリームファイルの構成です。

Stream_CR レコード、Stream_LF レコード、Stream_CRLF レコード
Stream_CR レコード、Stream_LF レコード、Stream_CRLF レコードは可変長レコードです。レコード長は、カウントによってではなく、データに埋め込まれた明示的なレコード区切り文字によって示されます。これらの区切り文字は、ストリーム形式のファイルにレコードを書き出したときに自動的に追加され、レコードを読み取ったときに削除されます。
レコード区切り文字は、1 バイトまたは 2 バイトです。
Stream_CR ファイルは、キャリッジリターンのみを区切り文字として使用するため、Stream_CR ファイルにはキャリッジリターン文字を含めてはなりません。
Stream_LF ファイルは、ラインフィードのみをレコード区切り文字として使用するため、Stream_LF にはラインフィード文字を含めてはなりません。これは、Linux* システムおよび macOS* システムにおける通常のテキストファイルのレコード型です。
Stream_CRLF ファイルは、キャリッジリターン/ラインフィードのペアのみをレコード区切り文字として使用するため、Stream_CRLF にはキャリッジリターン文字またはラインフィード文字を含めてはなりません。これは、Windows* システムにおける通常のテキストファイルのレコード型です。
レコード型を選択する際のガイドライン
レコード型を選択する前に、アプリケーションでどちらのデータ (書式なしまたは書式付き) を使用するかを検討してください。書式付きデータを使用する場合は、セグメント以外のレコード型を選択できます。書式なしデータを使用する場合は、Stream、Stream_CR、Stream_LF、Stream_CRLF レコード型は使用しないでください。
セグメントレコード型は、シーケンシャル・ファイルで書式なしシーケンシャル・アクセスにのみ使用できます。セグメントレコードは、インテル® Fortran 以外の言語で記述されたプログラムにより読み取られるファイルに対しては使用できません。
Stream、Stream_CR、Stream_LF、Stream_CRLF およびセグメントの各レコード型は、シーケンシャル・ファイルでのみ使用できます。
デフォルトのレコード型 (RECORDTYPE) は、OPEN 文に対する ACCESS 指定子および FORM 指定子の値により異なります。RECORDTYPE= 指定子はストリームアクセスでは無視されます。
ファイルのレコード型は、ファイル属性としては保持されません。ファイルの作成時に指定したレコード型以外のレコード型を使用した場合、結果は不定です。
I/O レコードは、論理的に関連付けられるフィールド (データ項目) の集合であり、通常は 1 つの単位として処理されます。
ノンアドバンシング I/O (ADVANCE 指定子) を指定しない限り、各インテル® Fortran I/O 文は、最低 1 つのレコードを転送します。
書式なしファイルでの区切り文字の指定
FOR_FMT_TERMINATOR 環境変数を使用して、明示的な RECORDTYPE= 指定子がない Fortran 書式付きファイルの区切り文字の値を指定します。
FOR_FMT_TERMINATOR 環境変数は、プログラムの開始時に 1 度だけ処理されます。特定のユニットに対してこの環境変数が指定した内容は、プログラムの終了時まで継続されます。
特定のレコード区切り文字を持つユニットの番号を指定できます。これらのユニット番号を使用する READ/WRITE 文では、指定されたレコード区切り文字が使用されます。他の READ/WRITE 文は、通常どおり動作します。
OPEN 文の RECORDTYPE= 指定子は、FOR_FMT_TERMINATOR によって設定された値を上書きします。FOR_FMT_TERMINATOR 値は、ACCESS='STREAM' ファイルでは無視されます。
FOR_FMT_TERMINATOR の一般構文
この環境変数の構文は、次のとおりです。
FOR_FMT_TERMINATOR=MODE[:ULIST][;MODE[:ULIST]]
説明:
MODE=CR | LF | CRLF ULIST = U | ULIST,U U = decimal | decimal - decimal
MODE は、使用されるレコード区切り文字を指定します。キーワード CR は、レコードがキャリッジリターンで終了することを意味します。キーワード LF は、レコードがラインフィードで終了することを意味します。これは、Linux* システムと macOS* システムのデフォルトです。キーワード CRLF は、レコードがキャリッジリターン/ラインフィードのペアで終了することを意味します。これは、Windows* システムのデフォルトです。
各リストメンバーの U とは、シンプルユニット番号または範囲としてのユニット数です。リストメンバーの上限は、64 です。
decimal は、負でない小数で 232 よりも小さな値です。
FOR_FMT_TERMINATOR 値の中では、スペースは使用できません。
BASH シェルの変数設定のコマンドライン (Linux*):
Sh: export FOR_FMT_TERMINATOR=MODE:ULIST
注
セミコロンがある場合は、環境変数値を引用符で囲む必要があります。
例:
次の例は、ユニット番号 10、11、12 の入力/出力操作に、キャリッジリターン/ラインフィードのペアで終了するレコードを指定します。
FOR_FMT_TERMINATOR=CRLF:10-12