概要
決定性のある分割/結合動作を使用して、範囲のリダクションを計算します。
ヘッダー
#include "tbb/parallel_reduce.h"
構文
template<typename Range, typename Value,
typename Func, typename Reduction>
Value parallel_deterministic_reduce( const Range& range,
const Value& identity, const Func& func,
const Reduction& reduction,
[, task_group_context& group] );
template<typename Range, typename Body>
void parallel_deterministic_reduce( const Range& range,
const Body& body
[, task_group_context& group] );
説明
parallel_deterministic_reduce テンプレートは、parallel_reduce テンプレートによく似ています。関数形式と命令形式があり、Func と Reduction の要件も似ています。
parallel_reduce とは異なり、parallel_deterministic_reduce は、Body と Range の分割動作およびボディーの結合動作に関して決定性があります。関数形式では、Func は決定性のある Range のセットに適用され、Reduction は決定性のある順序で部分的な結果のマージを行います。parallel_deterministic_reduce は、常に simple_partitioner を使用します。ほかのパーティショナーはランダムなワークスチール動作に反応するためです。したがって、テンプレート宣言にはパーティショナー引数がありません。
注意
simple_partitioner は自動的に範囲を粗くしないため、適切な粒度を指定していることを確認してください。詳細は、「パーティショナー」セクションを参照してください。
parallel_deterministic_reduce は常に、各範囲分割に対して Body 分割コンストラクターを呼び出します。
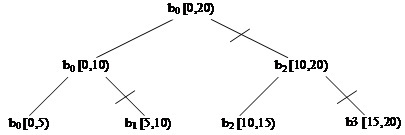
その結果、parallel_deterministic_reduce は、範囲が分割できなくなるまで再帰的に範囲を分割し、各サブ範囲に対して (Body 分割コンストラクターを呼び出して) 新しいボディーを作成します。parallel_reduce と同様に、各ボディー分割に対してボディーから結果をマージするために join メソッドが呼び出されます。上記の図は、サンプル範囲での parallel_deterministic_reduce の実行を示しています。斜線 (/) は、どこでボディーの新しいインスタンスが作成されたかを示します。
指定された引数に対して、parallel_deterministic_reduce は、実行スレッド数やスレッドへのタスクの割り当て方法に関係なく、同じ分割および結合操作のセットを実行します。ユーザー定義関数に決定性がある場合 (つまり、同じ入力データで実行したときに毎回同じ結果が出力される場合)、parallel_deterministic_reduce の複数の呼び出しは同じ結果になります。ただし、等価なシーケンシャル・アルゴリズムの結果 k とは異なる場合があります。
計算量
範囲とボディーが O(1) 空間を使用して範囲をほぼ等しい断片に分割する場合、空間計算量は O(P log(N)) です。ここで、N は範囲のサイズ、P はスレッド数です。
サンプル
parallel_reduce セクションのサンプルは、parallel_deterministic_reduce を使用するように簡単に修正できます。parallel_reduce を parallel_deterministic_reduce に変更するだけです。パーティショナーがある場合は、コンパイルエラーにならないように削除します。パフォーマンスが低下する場合は、blocked_range の粒度を指定する必要があります。
#include <numeric>
#include <functional>
#include "tbb/parallel_reduce.h"
#include "tbb/blocked_range.h"
using namespace tbb;
float ParallelSum( float array[], size_t n ) {
size_t grain_size = 1000;
return parallel_deterministic_reduce(
blocked_range<float*>( array, array+n, grain_size[ ),
0.f,
[](const blocked_range<float*>& r, float value)->float {
return std::accumulate(r.begin(),r.end(),value);
},
std::plus<float>());
}