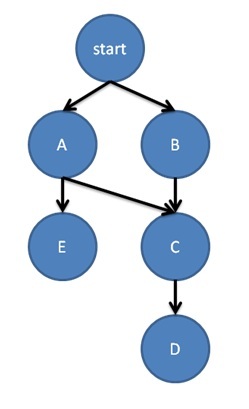
次の例では、A-E の 5 つの計算が下記の図のように半順序でセットアップされています。フローグラフの各エッジで、エッジの最後のノードは、先頭のノードが開始する前に実行を完了していなければなりません。
注
これは単純な構文の例にすぎません。フローグラフの各ノードは独立したタスクとして実行されるため、各ノードの粒度は、『インテル® TBB 入門チュートリアル』で説明されているタスクの一般的なガイドラインに従ってください。
#include <cstdio>
#include "tbb/flow_graph.h"
using namespace tbb::flow;
struct body {
std::string my_name;
body( const char *name ) : my_name(name) {}
void operator()( continue_msg ) const {
printf("%s\n", my_name.c_str());
}
};
int main() {
graph g;
broadcast_node< continue_msg > start;
continue_node<continue_msg> a( g, body("A"));
continue_node<continue_msg> b( g, body("B"));
continue_node<continue_msg> c( g, body("C"));
continue_node<continue_msg> d( g, body("D"));
continue_node<continue_msg> e( g, body("E"));
make_edge( start, a );
make_edge( start, b );
make_edge( a, c );
make_edge( b, c );
make_edge( c, d );
make_edge( a, e );
for (int i = 0; i < 3; ++i ) {
start.try_put( continue_msg() );
g.wait_for_all();
}
return 0;
}
この例で、ノード A-E は自身の名前を出力します。そのため、これらのノードはすべて、struct body を使用してボディー・オブジェクトを構築できます。
main 関数で、フローグラフは一回セットアップされ、3 回実行されます。この例のノードはすべて、周囲に continue_msg オブジェクトを渡します。ノードが実行を完了したことを通知するために使用されます。
main 関数の最初の行は、graph オブジェクト g を具体化します。次の行で、名前が start の broadcast_node が作成されます。このノードに渡されるものはすべて、そのサクセサーにブロードキャストされます。start ノードは、main の下部の for ループで残りのフローグラフを実行するために使用されます。
例では、名前が a - e の 5 つの continue_node オブジェクトが作成されます。各ノードは、グラフ graph g への参照とノードが実行するときに呼び出す関数オブジェクトで構築されます。サクセサー/プレデセッサーの関係は、ノードの宣言に続く make_edge 呼び出しでセットアップされます。
ノードとエッジがセットアップされると、for ループの各反復の try_put で、a と b に continue_msg がブロードキャストされます。a と b には 1 つのプレデセッサー (start) しかないため、どちらも 1 つの continue_msg を待ちます。
start からメッセージを受け取ると、ボディー・オブジェクトを実行します。完了すると、continue_msg をサクセサーに送ります。計算を並列に実行可能な場合、グラフは、複数のタスクを使用してノード間でメッセージを送る処理と、ノードのボディーを実行する処理を並列に実行します。
この例で使用されているクラスと関数は、「フローグラフ」からリンクされているトピックで詳細に説明されています。