単純な関数 Foo では、並列ループで記述された場合に大幅な速度向上が見込めません。原因は、プロセッサーとメモリー間のシステム帯域幅が不十分なためです。この場合、キャッシュを活用することを考えてアルゴリズムを検討する必要があります。キャッシュの利用を考慮した構造の見直しは、シリアルプログラムはもちろん、並列プログラムでも有益です。
一部のケースでは作業を再構成する代わりに affinity_partitioner を使用します。このパーティショナーは、粒度を自動的に選択するだけでなく、キャッシュ・アフィニティーを最適化して、スレッド間のデータを均等に分散しようとします。affinity_partitioner を使用すると、次の場合にパフォーマンスを大幅に向上できます。
-
計算でデータアクセスごとにいくつかの操作を行う場合。
-
ループによって処理されたデータがキャッシュに配置される場合。
-
ループまたは同様のループが同じデータに対して再実行される場合。
-
2 つ以上のハードウェア・スレッドが利用できる (特にスレッド数が 2 の累乗でない場合)。2 スレッドのみ利用可能な場合、インテル® スレッディング・ビルディング・ブロック (インテル® TBB) のデフォルトのスケジュールで、十分なキャッシュ・アフィニティーが通常提供されます。
次のコードは、affinity_partitioner の使用方法を示しています。
#include "tbb/tbb.h"
void ParallelApplyFoo( float a[], size_t n ) {
static affinity_partitioner ap;
parallel_for(blocked_range<size_t>(0,n), ApplyFoo(a), ap);
}
void TimeStepFoo( float a[], size_t n, int steps ) {
for( int t=0; t<steps; ++t )
ParallelApplyFoo( a, n );
}
サンプルで、affinity_partitioner オブジェクト ap はループの反復間で生存します。ループの反復がどこで実行されたかを記憶しているため、以前実行した同じスレッドに反復を渡すことができます。サンプルコードでは、affinity_partitioner をローカル・スタティック・オブジェクトとして宣言することにより、パーティショナーの寿命を取得しています。別のアプローチは、TimeStepFoo の反復ループの外でアフィニティーを宣言して、parallel_for に渡す方法です。
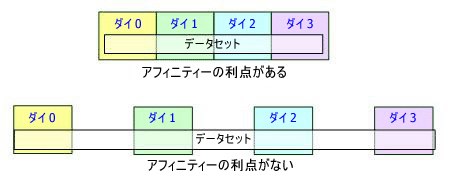
データがシステムのキャッシュに格納できない場合、利点はほとんどありません。次の図は、この状況を示しています。
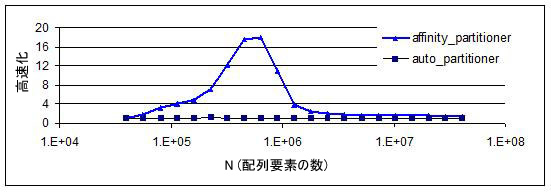
次の図は、並列処理の高速化がデータセットのサイズに応じてどのように変化するかを示しています。サンプルの計算は、A[i]+=B[i] で、i の範囲は [0,N) です。この条件は、大きな変化を示すために選択されたものです。通常のコードではこのように大きな変化は起こりません。グラフの両端はあまり高速化されていません。N が小さい場合、並列スケジュールのオーバーヘッドが大きくなるため、あまり高速化されません。N が大きい場合、データセットが大きくなるため、ループ間でキャッシュに格納して処理できません。中間のピークがアフィニティーのスイートスポットです。したがって、メモリーアクセスに対する計算の比率が低い場合は、affinity_partitioner を万能薬ではなく単なるツールと考えるべきです。
|
最適化に関する注意事項 |
|---|
|
インテル® コンパイラーでは、インテル® マイクロプロセッサーに限定されない最適化に関して、他社製マイクロプロセッサー用に同等の最適化を行えないことがあります。これには、インテル® ストリーミング SIMD 拡張命令 2、インテル® ストリーミング SIMD 拡張命令 3、インテル® ストリーミング SIMD 拡張命令 3 補足命令などの最適化が該当します。インテルは、他社製マイクロプロセッサーに関して、いかなる最適化の利用、機能、または効果も保証いたしません。本製品のマイクロプロセッサー依存の最適化は、インテル® マイクロプロセッサーでの使用を前提としています。インテル® マイクロアーキテクチャーに限定されない最適化のなかにも、インテル® マイクロプロセッサー用のものがあります。この注意事項で言及した命令セットの詳細については、該当する製品のユーザー・リファレンス・ガイドを参照してください。 注意事項の改訂 #20110804 |