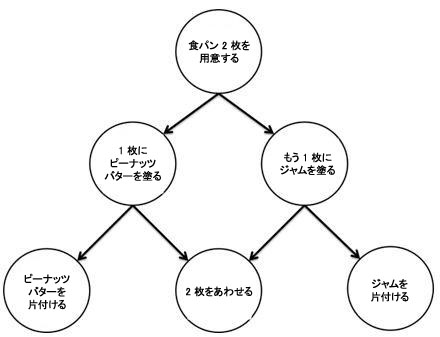
依存関係グラフでは、ノードは計算を実行するボディー・オブジェクトを呼び出し、エッジはこれらの計算の半順序を作成します。ランタイムに、指定された半順序で有効な場合、ライブラリーはボディー・オブジェクトを実行するタスクをスポーンしてスケジュールします。次の図は、依存関係グラフを使用して表現できるアプリケーションの例です。
依存関係グラフは特別なケースのデータフロー・グラフで、ノード間で渡されるデータが tbb::flow::continue_msg 型になります。一般的なデータフロー・グラフとは異なり、依存関係グラフのノードは受け取るメッセージごとにタスクをスポーンしません。代わりに、プレデセッサーの数を認識し、受け取るメッセージ数をカウントして、カウントがプレデセッサーの総数と等しい場合にのみ、タスクをスポーンしてボディーを実行します。
次の図は、依存関係グラフの別の例です。上の図とトポロジーは同じですが、サンドイッチを作る手順が単純な関数に置き換えられています。この半順序で、関数 A はほかの計算が実行を開始する前に完了している必要があります。関数 B は、C と D が実行を開始する前に完了している必要があります。また、E は、D と F が実行を開始する前に完了している必要があります。B と E、そして C と F の間に明示的な実行順序がないため、これは半順序です。
この依存関係グラフをフローグラフとして実装するため、continue_node オブジェクトをノードと continue_msg オブジェクトに (メッセージとして) 使用します。continue_node コンストラクターには、2 つの引数を指定します。
template< typename Body > continue_node( graph &g, Body body)
第 1 引数は属するグラフ、第 2 引数は関数オブジェクトまたはラムダ式です。function_node とは異なり、continue_node の同時実行数は常に unlimited であると仮定され、依存関係が満たされると直ちにタスクをスポーンします。
次のコードは、この図の例の実装です。
typedef continue_node< continue_msg > node_t;
typedef const continue_msg & msg_t;
int main() {
tbb::flow::graph g;
node_t A(g, [](msg_t){ a(); } );
node_t B(g, [](msg_t){ b(); } );
node_t C(g, [](msg_t){ c(); } );
node_t D(g, [](msg_t){ d(); } );
node_t E(g, [](msg_t){ e(); } );
node_t F(g, [](msg_t){ f(); } );
make_edge(A, B);
make_edge(B, C);
make_edge(B, D);
make_edge(A, E);
make_edge(E, D);
make_edge(E, F);
A.try_put( continue_msg() );
g.wait_for_all();
return 0;
}
このグラフの実行例を次に示します。D の実行は、B と E の両方が完了するまで開始されません。タスクが wait_for_all で待機している間、そのスレッドはインテル® TBB ワークプールのほかのタスクを実行することができます。
フローグラフの実行がすべて非同期に行われることに注目することは重要です。A.try_put を呼び出すと、カウンターをインクリメントして A のボディーを実行するタスクをスポーンした後、呼び出しスレッドに制御を返します。同様に、ボディータスクはラムダ式を実行し、すべてのサクセサーノードへ continue_msg を送ります (サクセサーノードがある場合)。wait_for_all の呼び出しのみブロックします。このケースでも、待機している間、呼び出しスレッドはインテル® TBB ワークプールのほかのタスクを実行することができます。
上記のタイムラインは、並列に同時実行できるすべてのタスクを実行するのに十分なスレッドがある場合のシーケンスを示しています。スレッド数が少ない場合、スポーンされるいくつかのタスクで、スレッドが実行に利用できるようになるまで待つ必要があります。