問題
並列化の粒度が細かすぎて、並列スケジュールや通信のオーバーヘッドが大きすぎる。
コンテキスト
多くのアルゴリズムでは、タスクあたりの命令数が少ない、非常に細かな粒度で並列化を行うことができます。しかし、スレッド間の同期には通常、桁違いに大きなサイクル数が必要になります。例えば、2 つの配列の要素単位の加算は完全に並列に行うことができますが、スカラー加算が別のタスクとしてスケジュールされた場合、ほとんどの時間は加算ではなく同期に費やされるでしょう。
影響
-
個々の計算は並列に行うことが可能ですが、小さいものです。インテル® スレッディング・ビルディング・ブロック (インテル® TBB) の実用的な処理では、「小さい」とは 10,000 サイクル未満を意味します。
-
並列化はパフォーマンス向上が目的であり、セマンティクス上の理由から必要なわけではありません。
ソリューション
計算のグループをブロックにします。ブロック内の計算をシリアルに評価します。
ブロックサイズは (並列化のオーバーヘッドを考慮してもメリットがある) 十分な大きさにしてください。ブロックサイズが大きすぎると、ブロック数が非常に少なくなり、プロセッサー間で均等に処理を分散できなくなるため、並列化やロード・バランシングが制限されることがあります。
ブロックサイズは通常、次の 2 点を考慮して決定します。
-
ブロック間の同期を最小限にする。
-
ブロック間のキャッシュ・トラフィックを最小限にする。
計算が完全に独立していて、ブロックも独立している場合、キャッシュ・トラフィックのみを考慮してください。
ループが「小さい」場合 (10,000 クロックサイクル未満の場合)、最適な集合が単一ブロックになるため、ループを並列化するのは非実用的です。
サンプル
範囲 引数が指定できるインテル® TBB のループ・テンプレート (tbb::parallel_for など) は、自動凝集化をサポートしています。
凝集化を行うときは、キャッシュの影響を考慮してください。可能であれば、キャッシュラインがグループ間をまたがないようにしてください。
キャッシュライン境界は内部のレートに影響します。例えば、計算で 2D グリッドが形成され、最も近いポイントとのみ通信する場合、ブロックごとの計算は (ブロックのエリアで) 2 次的に増加しますが、ブロック間の通信は (ブロックの周囲で) 直線的に増加します。次の図は、8x8 グリッドを凝集化する 4 つの異なる方法を示しています。このような解析を行う場合、キャッシュライン単位で転送される情報を考慮するようにしてください。ここでは、ブロックが論理グリッドに関して正方形ではなく、キャッシュラインのグリッドに関して正方形の場合に、周囲が最小になります。

ベクトル化についても考慮してください。長い連続したデータのサブセットを含むブロックには、ベクトル化が有効です。
再帰計算では、ほとんどの処理は木構造の葉ノードで行われます。ソリューションは、次の図で示されているように、グループを部分木として扱うことです。
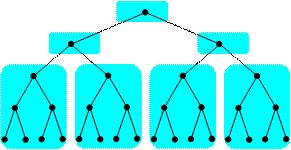
多くの場合、このような凝集化は、あるしきい値に達すると再帰的に続けて行われます。例えば、再帰ソートは、特定のしきい値を超えた場合にのみ部分問題を並列に解きます。
参考資料
用語 "agglomeration" (凝集化) は、Ian Foster が著書 Designing and Building Parallel Programs (http://www.mcs.anl.gov/~itf/dbpp) で使用したものです。Agglomeration は、4 ステップの PCAM 設計法の一部にも含まれています。
-
Partitioning (分割) - プログラムをできるだけ小さなタスクに分割します。
-
Communication (通信) – タスク間で必要な通信を特定します。インテル® TBB を使用する場合、通常はキャッシュラインの転送を使用します。これは自動で行われますが、タスク間で起きていることを理解すると、凝集化ステップを進めやすくなります。
-
Agglomeration (凝集化) – タスクを組み合わせてより大きなタスクにします。彼の書籍には、さまざまな考察の広範なリストが含まれています。
-
Mapping (マッピング) – タスクをプロセッサーにマップします。インテル® TBB では、タスク・スケジューラーがこのステップを行います。