以下ループは、リダクションを行うことができます。
float SerialSumFoo( float a[], size_t n ) {
float sum = 0;
for( size_t i=0; i!=n; ++i )
sum += Foo(a[i]);
return sum;
}
反復が独立している場合、次のように parallel_reduce テンプレート・クラスを使用して、このループを並列化できます。
float ParallelSumFoo( const float a[], size_t n ) {
SumFoo sf(a);
parallel_reduce( blocked_range<size_t>(0,n), sf );
return sf.my_sum;
}
SumFoo クラスでは、サブ合計を集積して結合する方法など、リダクションの詳細を記述します。SumFoo クラスの定義は次のようになります。
class SumFoo {
float* my_a;
public:
float my_sum;
void operator()( const blocked_range<size_t>& r ) {
float *a = my_a;
float sum = my_sum;
size_t end = r.end();
for( size_t i=r.begin(); i!=end; ++i )
sum += Foo(a[i]);
my_sum = sum;
}
SumFoo( SumFoo& x, split ) : my_a(x.my_a), my_sum(0) {}
void join( const SumFoo& y ) {my_sum+=y.my_sum;}
SumFoo(float a[] ) :
my_a(a), my_sum(0)
{}
};
parallel_for の ApplyFoo クラスとは異なることに注意してください。まず、operator() は const ではありません。これは、SumFoo::sum を更新しなければならないためです。次に、SumFoo には分割コンストラクター があり、parallel_reduce が機能するために join メソッドがなければなりません。分割コンストラクターの引数は、オリジナル・オブジェクトへの参照と、ライブラリーによって定義される型 split の仮引数です。この仮引数によって、分割コンストラクターとコピー・コンストラクターが区別されます。
ヒント
サンプルの operator() の定義では、ループ内部でアクセスされるスカラー値にローカル一時変数 (a, sum, end) を使用しています。この手法は、値をメモリーの代わりにレジスターに保持できることをコンパイラーに伝えることにより、パフォーマンスを向上させます。値が大きすぎてレジスターに格納できない場合、またはコンパイラーがこの手法に対応できない場合、この手法を使用してもパフォーマンスは向上しません。一般的な最適化コンパイラーでは、ループはほかの場所に書き込みを行わず、ループの外でほかの読み取りを行わないことをコンパイラーが推測するため、ローカル一時変数を書き込み変数 (サンプルの sum など) に使用するだけで十分です。
タスク・スケジューラーでワーカースレッドが利用できると判断された場合、parallel_reduce は分割コンストラクターを呼び出してワーカーのサブタスクを作成します。サブタスクが完了すると、parallel_reduce は join メソッドを使用してサブタスクの結果を集積します。次の図の上のチャートは、ワーカーが利用可能な場合に発生する分割と結合のシーケンスを示しています。
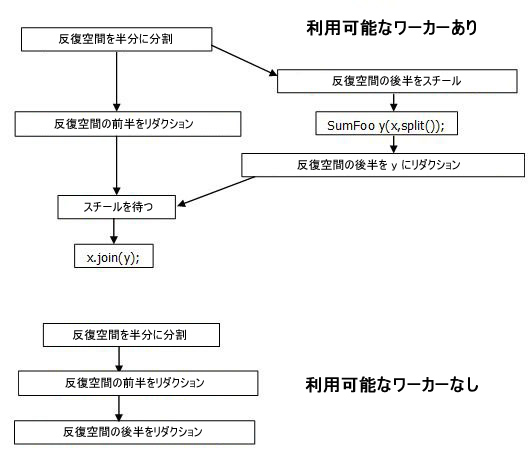
上記の図の矢印は時間軸で順序を示しています。前半のリダクションでオブジェクト x が使用される間に、分割コンストラクターが同時に実行される可能性があります。そのため、y を作成する分割コンストラクターのすべての動作が、x に関してスレッドセーフである必要があります。分割コンストラクターでほかのオブジェクトと共有の参照カウントをインクリメントする必要がある場合は、アトミック・インクリメントを使用しなければなりません。
ワーカーが利用できない場合、反復の前半のリダクションを行った同じボディー・オブジェクトを使用して後半のリダクションが行われます。つまり、前半のリダクションが終了したところで後半のリダクションが開始します。
警告
ワーカーが利用できない場合は分割と結合が使用されないため、parallel_reduce は必ずしも再帰的な分割を行いません。
警告
同じボディーが複数のサブ範囲の集積に使用される可能性があるため、operator() が以前の集積を破棄しないことは問題です。次のコードは、SumFoo::operator() の誤った定義を示しています。
class SumFoo {
...
public:
float my_sum;
void operator()( const blocked_range<size_t>& r ) {
...
float sum = 0; // WRONG – should be 'sum = my_sum".
...
for( ... )
sum += Foo(a[i]);
my_sum = sum;
}
...
};
誤った定義では、parallel_reduce が適用されるすべてのサブ範囲ではなく、最後のサブ範囲の部分和をボディーが返しています。
parallel_reduce のパーティショナーと粒度の規則は、parallel_for と同じです。
parallel_reduce は、あらゆる結合操作を一般化します。一般に、分割コンストラクターでは、2 つのことが行われます。
-
ループボディーを実行するために必要な読み取り専用情報をコピーする。
-
リダクション変数を初期化して操作要素を特定する。
join メソッドは、対応するマージ操作を行います。複数のリダクションを同時に行うことが可能です。単一の parallel_reduce で最小値と最大値を同時に求めることができます。
注
リダクション操作は可換的でない場合があります。浮動小数点の加算が文字列の連結に置換されても、サンプルは動作します。