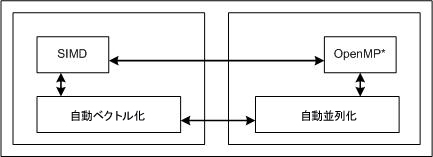
ユーザー指示または SIMD ベクトル化は、OpenMP* 並列化が自動並列化を補足するように、自動ベクトル化を補足します。下記の図でこの関係を示します。ユーザー指示によるベクトル化は SIMD (Single-Instruction, Multiple-Data) 機能として実装され、SIMD ベクトル化と呼ばれます。
注
SIMD ベクトル化機能は、インテル製マイクロプロセッサーおよび互換マイクロプロセッサーの両方で利用可能です。ベクトル化により呼び出されるライブラリー・ルーチンは、互換マイクロプロセッサーよりもインテル製マイクロプロセッサーにおいてより優れたパフォーマンスが得られる可能性があります。また、ベクトル化は、/arch (Windows*)、-m (Linux* および macOS*)、[Q]x などの特定のオプションによる影響を受けます。
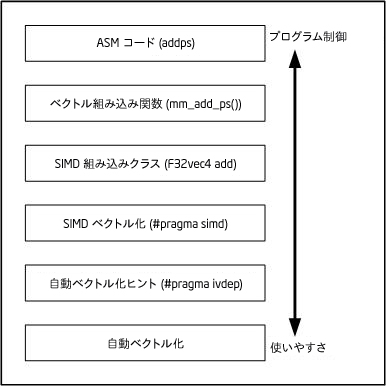
次の図は、ハードウェアのベクトル化機能を活用するベクトル化コードを生成するためのさまざまなアプローチの中で、SIMD ベクトル化がどこに位置付けされているかを示しています。SIMD ベクトル化を用いて記述されたプログラムは、自動ベクトル化ヒントを使用して記述されたものと似ています。SIMD ベクトル化を使用すると、ベクトル化コードの取得に必要なコードの変更を最小限にすることができます。
SIMD ベクトル化は #pragma omp simd プラグマを使用してループをベクトル化します。ループにこのディレクティブを追加して、ループがベクトル化されるように -qopenmp-simd (Linux* または macOS*) または /Qopenmp-simd (Windows*) オプションを指定して再コンパイルしなければなりません。
関数 add_floats() が不明なポインターを多く使用しているため、コンパイラーの自動ランタイム独立性チェックにより最適化が行われる C++ の例ついて考えてみます。#pragma ivdep の自動ベクトル化ヒントを使ってデータ依存性のアサーションを追加し、自動ベクトル化の最適化をループに適用するかどうかコンパイラーに判断させることができます。または、#pragma omp simd を使用して、このループのベクトル化を実行することができます。
#pragma omp simd なしの例 |
|---|
|
[D:/simd] icl -nologo -c -Qopt-report2 -Qopt-report-file=stderr -Qopt-report-phase=vec -Qopenmp-simd example1.c
example1.c
最適化レポート開始: add_floats(float *, float *, float *, float *, float *, int)
レポート: ベクトルの最適化 [vec]
ループの開始 C:\Users\test\run\example1.c(3,2)
リマーク #15344: ループはベクトル化されませんでした: ベクトル依存関係がベクトル化を妨げています。最初の依存関係を以下に示します。詳細については、レベル 5 のレポートを使用してください。
リマーク #15346: ベクトル依存関係: FLOW の依存関係が a[i] (4:3) と b[i] (4:3) の間に仮定されました。
ループの終了
ループの開始 C:\Users\test\run\example1.c(3,2)
<剰余>
ループの終了
===========================================================================
|
#pragma omp simd ありの例 |
|
[D:/simd] icl -nologo -c -Qopt-report2 -Qopt-report-file=stderr -Qopt-report-phase=vec -Qopenmp-simd example1.c
example1.c
最適化レポート開始: add_floats(float *, float *, float *, float *, float *, int)
レポート: ベクトルの最適化 [vec]
ループの開始 C:\iUsers\test\run\example1.c(4,2)
<ベクトル化のピールループ>
ループの終了
ループの開始 C:\iUsers\test\run\example1.c(4,2)
リマーク #15301: OpenMP* SIMD ループがベクトル化されました。
ループの終了
ループの開始 C:\iUsers\test\run\example1.c(4,2)
<別の境界でアライメントされたベクトルループ>
ループの終了
ループの開始 C:\iUsers\test\run\example1.c(4,2)
<ベクトル化の剰余ループ>
リマーク #15301: 剰余ループがベクトル化されました
ループの終了
ループの開始 C:\iUsers\test\run\example1.c(4,2)
<ベクトル化の剰余ループ>
ループの終了
===========================================================================
|
#pragma omp simd と自動ベクトル化ヒントの主な違いは、#pragma omp simd では、コンパイラーはループをベクトル化できない場合に警告を発行します。自動ベクトル化ヒントでは、#pragma vector always ヒントを使用した場合でも、実際のベクトル化はコンパイラーの判断にまかせられます。
#pragma omp simd にはオプション節があり、コンパイラーにベクトル化の方法を指示できます。コンパイラーが正しいベクトル化コードを生成するための十分な情報を得られるように、これらの節を適切に使用してください。節についての詳細は、#pragma omp simd の説明を参照してください。
追加のセマンティクス
omp simdプラグマの使用に関して、次の点に注意してください。
変数は private、linear、reduction のいずれかに属します (またはいずれにも属しません)。
ベクトルループ内では、private、linear、reduction の場合、式はベクトル値として評価されます。または、ベクトル値に評価される部分式があります。そうでない場合、スカラー値として評価されます (つまり、同じ値をすべての反復にブロードキャストします)。スカラー値は、よくループ不変として使用されますが、必ずしもループ不変であるわけではありません。
ベクトル値はスカラー型の左辺値へ割り当てられません。エラーになります。
スカラー型の左辺値はベクトル条件下では割り当てられません。エラーになります。
switch 文はサポートされていません。
注
一部の自動ベクトル化が可能なループでは、SIMD プラグマを使用してベクトル・セマンティクスを表現するのは難しいかもしれません。例えば、C には MIN/MAX 演算子がないため、C で MIN/MAX リダクションを表現するのは困難です。
vector 宣言の使用
数学関数 sinf() が含まれるループを持つ次の C++ の例ついて考えてみます。
注
このセクションで示すコード例はすべて Windows* の C/C++ のみが対象です。数学関数を持つループが自動ベクトル化する例 |
|---|
|
[D:/simd] icl -nologo -c -Qrestrict -Qopt-report2 -Qopt-report-file=stderr -Qopt-report-phase=vec example2.c
example2.c
最適化レポート開始: vsin(float *restrict, float *restrict, int)
レポート: ベクトルの最適化 [vec]
ループの開始 C:\Users\test\run\example2.c(3,1)
<ベクトル化のピールループ>
ループの終了
ループの開始 C:\Users\test\run\example2.c(3,1)
リマーク #15300: ループがベクトル化されました。
ループの終了
ループの開始 C:\Users\test\run\example2.c(3,1)
<別の境界でアライメントされたベクトルループ>
ループの終了
ループの開始 C:\Users\test\run\example2.c(3,1)
<ベクトル化の剰余ループ>
ループの終了
=========================================================================== |
上記のコードをコンパイルすると、sinf() 関数を持つループは適切な SVML (Short Vector Mathematical Library) ライブラリー関数 (インテル® C++ コンパイラーにより提供される) を使用して自動ベクトル化されます。自動ベクトル化はエントリーポイントを識別し、スカラー数学ライブラリー関数に対応する SVML 関数を探し、起動します。
このループ内に sinf() と同じプロトタイプを持つユーザー定義関数 foo() への呼び出しがある場合、この呼び出しで foo() がインライン展開されていない限り、自動ベクトル化はこの関数が何をするか分からないため、ループのベクトル化に失敗します。
ユーザー定義関数を持つループが自動ベクトル化しない例 |
|---|
|
[D:/simd] icl -nologo -c -Qrestrict -Qopt-report2 -Qopt-report-file=stderr -Qopt-report-phase=vec example2.c
example2.c
最適化レポート開始: vsin(float *restrict, float *restrict, int)
レポート: ベクトルの最適化 [vec]
最適化できないループ:
ループの開始 C:\Users\test\run\example2.c(3,1)
リマーク #15543: ループはベクトル化されませんでした: 関数の呼び出しを持つループは最適化の候補と見なされません。
ループの終了
|
このような場合、__declspec(vector) (Windows*) または __attribute__((vector)) (Linux*) 宣言を使用してループをベクトル化できます。vector 宣言を関数宣言に加えて、呼び出し元と呼び出し先の両コードを再コンパイルするだけで、ループと関数がベクトル化されます。
simd 宣言のあるユーザー定義関数を持つループがベクトル化する例 |
|---|
|
[D:/simd] bash-3.2$ icl -nologo -c -Qopenmp-simd -Qrestrict -Qopt-report1 -Qopt-report-file=stderr -Qopt-report-phase=vec example3.c
example3.c
最適化レポート開始: vfoo(float *restrict, float *restrict, int)
レポート: ベクトルの最適化 [vec]
ループの開始 C:\Users\test\run\example3.c(7,5)
<ベクトル化のピールループ>
ループの終了
ループの開始 C:\Users\test\run\example3.c(7,5)
リマーク #15300: ループがベクトル化されました。
ループの終了
ループの開始 C:\Users\test\run\example3.c(7,5)
<別の境界でアライメントされたベクトルループ>
ループの終了
ループの開始 C:\Users\test\run\example3.c(7,5)
<ベクトル化の剰余ループ>
ループの終了
===========================================================================
最適化レポート開始: foo.._simdsimd3__xmm4nv(float)
レポート: ベクトルの最適化 [vec]
リマーク #15347: 関数がベクトル化されました: xmm、simdlen=4、マスクなし、仮引数の型: (vector)
===========================================================================
最適化レポート開始: foo.._simdsimd3__xmm4mv(float)
レポート: ベクトルの最適化 [vec]
リマーク #15347: 関数がベクトル化されました: xmm、simdlen=4、マスク付き、仮引数の型: (vector)
=========================================================================== |
#pragma omp declare simd 宣言の使用に関する制約
ベクトル化は、ハードウェアとソースコードのスタイルという 2 つの主な要因により制約されます。vector 宣言を使用する場合、使用できない機能は次のとおりです。
_Cilk_spawn、_Cilk_for、OpenMP* parallel/for/sections/task/target/teams、および明示的なスレッド API 呼び出しによるスレッドの生成と join
ロック、バリア、atomic 構文、クリティカル・セクション (#pragma omp ordered simd ブロック内で許可される)
インライン・アセンブリー・コード、VM、ベクトル組込み関数 (例: SVML 組込み関数)
setjmp、longjmp、SHE、計算型 GOTO の使用
EH は許可されず、すべてのベクトル関数は noexcept と見なされる
switch 文 (場合によっては、if 文に変換されますが、必ず変換されるとは限りません)
exit()/abort() 呼び出し
非ベクトル関数呼び出しは、一般にベクトル関数内で許可されますが、そのような関数への呼び出しはレーン単位でシリアル化されるため、パフォーマンスが低下します。また、SIMD 対応関数では、引数による書き込みを除く副作用があってはなりません。非ベクトル関数は、この規則に反するため、SIMD 対応関数で実行する場合には注意が必要です。
仮引数は次のデータ型でなければなりません。
- 符号付き (なし) 8、16、32、または 64 ビット整数
- 32 または 64 ビット浮動小数点
- 64 または 128 ビット複素数
- ポインター (C++ 参照はポインター型と見なされる)